dockerCommand4Windows
java编码规范-基于alibaba的代码规范
alibaba的代码规范
阿里巴巴开发手册git地址:https://github.com/alibaba/p3c

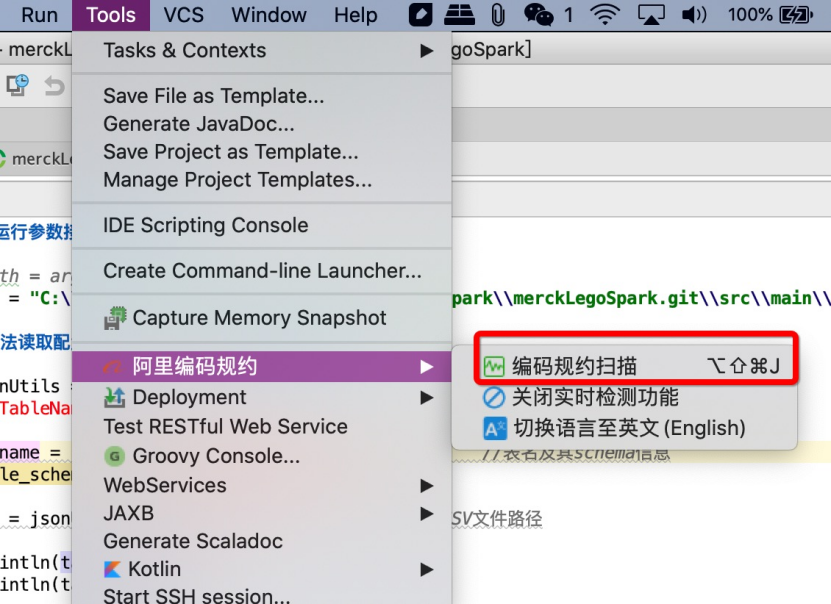
请使用如下插件,并遵守阿里编码规约

执行代码检查
代码样式
打开Window->Preferences->Java->Code Style->Code Templates
点击import 插入eclipse-codetemplate
(eclipse-codestyle.xml)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
<profiles version="12">
<profile kind="CodeFormatterProfile" name="P3C-CodeStyle" version="13">
<!--可变参数的... Idea没有对应的配置项,强制insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_ellipsis" value="insert"/>
<!--枚举值之间 Idea没有对应的配置项,强制insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_enum_declarations" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_invocation_arguments=Java:SPACE_BEFORE_COMMA-->
<!--org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_declaration_parameters=Java:SPACE_BEFORE_COMMA
由于IDEA只有一个SPACE_BEFORE_COMMA选项,所以统一设置 insert_space_before_comma 为 do not insert
-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_declaration_parameters"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_invocation_arguments"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_allocation_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_for_inits" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_method_declaration_throws"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_array_initializer"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_annotation" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_type_parameters"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_type_arguments" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_constructor_declaration_parameters"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_superinterfaces"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_parameterized_type_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_enum_declarations"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_enum_constant_arguments"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_multiple_local_declarations"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_for_increments" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_explicitconstructorcall_arguments"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_constructor_declaration_throws"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_comma_in_multiple_field_declarations"
value="do not insert"/>
<!--insert_space_before_comma end-->
<!--org.eclipse.jdt.core.formatter.insert_space_after_comma_in_type_arguments=Java:SPACE_AFTER_COMMA_IN_TYPE_ARGUMENTS-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_type_arguments" value="insert"/>
<!--IDEA只有一个配置项SPACE_AFTER_COMMA,insert_space_after_comma*统一设置成insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_constructor_declaration_parameters"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_for_increments" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_multiple_local_declarations"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_explicitconstructorcall_arguments"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_and_in_type_parameter" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_for_inits" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_parameterized_type_reference"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_multiple_field_declarations"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_superinterfaces" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_array_initializer" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_method_invocation_arguments"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_constructor_declaration_throws"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_allocation_expression" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_method_declaration_parameters"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_method_declaration_throws"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_enum_constant_arguments"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_type_parameters" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_comma_in_annotation" value="insert"/>
<!--insert_space_after_comma end-->
<!--org.eclipse.jdt.core.formatter.insert_space_before_colon_in_conditional=Java:SPACE_BEFORE_COLON-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_conditional" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_assert" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_for" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_after_colon_in_conditional=Java:SPACE_AFTER_COLON-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_conditional" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_assert" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_for" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_labeled_statement" value="insert"/>
<!--IDEA不支持配置,默认do not insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_default" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_labeled_statement"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_colon_in_case" value="do not insert"/>
<!--这个在Eclipse也没有找到配置的地方-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_colon_in_case" value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_semicolon=Java:SPACE_BEFORE_SEMICOLON
程序导入的时候强制将SPACE_BEFORE_SEMICOLON设置为false
-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_semicolon_in_try_resources"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_semicolon" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_semicolon_in_for" value="do not insert"/>
<!--SPACE_AFTER_SEMICOLON=true-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_semicolon_in_for" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_semicolon_in_try_resources" value="insert"/>
<!--IDEA不支持配置,do not insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_enum_constant"
value="do not insert"/>
<setting
id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_annotation_type_member_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_constructor_declaration"
value="do not insert"/>
<!--IDEA不支持,使用默认-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_postfix_operator" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_postfix_operator" value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_after_binary_operator=Java:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_binary_operator" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_binary_operator" value="insert"/>
<!--IDEA不支持配置,使用如下值,两者对应-->
<setting
id="org.eclipse.jdt.core.formatter.insert_space_after_opening_angle_bracket_in_parameterized_type_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_angle_bracket_in_type_arguments"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_angle_bracket_in_type_parameters"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_angle_bracket_in_type_parameters"
value="insert"/>
<setting
id="org.eclipse.jdt.core.formatter.insert_space_before_opening_angle_bracket_in_parameterized_type_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_angle_bracket_in_type_arguments"
value="do not insert"/>
<setting
id="org.eclipse.jdt.core.formatter.insert_space_before_closing_angle_bracket_in_parameterized_type_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_angle_bracket_in_type_arguments"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_angle_bracket_in_type_parameters"
value="do not insert"/>
<!--Java:SPACE_BEFORE_OPENING_ANGLE_BRACKET_IN_TYPE_PARAMETER-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_angle_bracket_in_type_parameters"
value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_after_closing_angle_bracket_in_type_arguments=Java:SPACE_AFTER_CLOSING_ANGLE_BRACKET_IN_TYPE_ARGUMENT-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_angle_bracket_in_type_arguments"
value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_after_closing_brace_in_block=Java:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_brace_in_block" value="insert"/>
<!--IDEA使用了对应的配置:Java:SPACE_WITHIN_ARRAY_INITIALIZER_BRACES,但感觉不太好,IDEA默认不插入,Eclipse也使用不插入-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_brace_in_array_initializer"
value="do not insert"/>
<!--use default insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_parenthesized_expression_in_return"
value="insert"/>
<!--use default do not insert -->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_while" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_prefix_operator" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_prefix_operator" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_for" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_catch" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_switch" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_for" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_method_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_brackets_in_array_type_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_parenthesized_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_method_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_parens_in_method_invocation"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_method_invocation"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_try" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_if" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_try" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_bracket_in_array_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_if" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_synchronized"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_bracket_in_array_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_cast" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_synchronized"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_parenthesized_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_catch" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_method_invocation"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_method_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_annotation"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_brace_in_array_initializer"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_annotation"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_while" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_switch" value="do not insert"/>
<!--use default insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_anonymous_type_declaration"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_enum_constant" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_enum_declaration"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_annotation_type_declaration"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_constructor_declaration"
value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_and_in_type_parameter" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_parenthesized_expression_in_throw"
value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_switch=Java:SPACE_BEFORE_SWITCH_LBRACE-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_switch" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_type_declaration=Java:SPACE_BEFORE_CLASS_LBRACE-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_type_declaration"
value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_block=Java:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_block" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_array_initializer=Java:SPACE_BEFORE_ARRAY_INITIALIZER_LBRACE-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_array_initializer"
value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_method_declaration=Java:SPACE_BEFORE_METHOD_LBRACE-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_brace_in_method_declaration"
value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_after_question_in_conditional=Java:SPACE_AFTER_QUEST-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_question_in_conditional" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_question_in_conditional=Java:SPACE_BEFORE_QUEST-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_question_in_conditional" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_annotation=Java:SPACE_BEFORE_ANOTATION_PARAMETER_LIST-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_annotation"
value="do not insert"/>
<!--use default do not insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_question_in_wildcard" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_question_in_wildcard" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_ellipsis" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_brackets_in_array_allocation_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_enum_constant"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_constructor_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_bracket_in_array_allocation_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_at_in_annotation_type_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_at_in_annotation" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_at_in_annotation_type_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_parenthesized_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_enum_constant"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_constructor_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_paren_in_constructor_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_cast" value="do not insert"/>
<setting
id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_annotation_type_member_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_closing_paren_in_enum_constant"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_bracket_in_array_type_reference"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_opening_bracket_in_array_allocation_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_bracket_in_array_allocation_expression"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_bracket_in_array_reference"
value="do not insert"/>
<!--下面两个对应IDEA中的一个配置Java:SPACE_AROUND_ASSIGNMENT_OPERATORS,使用insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_assignment_operator" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_assignment_operator" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_catch=Java:SPACE_BEFORE_CATCH_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_catch" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_method_invocation=Java:SPACE_BEFORE_METHOD_CALL_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_method_invocation"
value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_try=Java:SPACE_BEFORE_TRY_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_try" value="insert"/>
<!--下面两个对应IDEA中的一个配置Java:SPACE_AROUND_UNARY_OPERATOR,使用do not insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_unary_operator" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_unary_operator" value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_if=Java:SPACE_BEFORE_IF_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_if" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_while=Java:SPACE_BEFORE_WHILE_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_while" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_after_closing_paren_in_cast=Java:SPACE_AFTER_TYPE_CAST-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_closing_paren_in_cast" value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_method_declaration=Java:SPACE_BEFORE_METHOD_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_method_declaration"
value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_for=Java:SPACE_BEFORE_FOR_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_for" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_synchronized=Java:SPACE_BEFORE_SYNCHRONIZED_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_synchronized" value="insert"/>
<!--org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_switch=Java:SPACE_BEFORE_SWITCH_PARENTHESES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_opening_paren_in_switch" value="insert"/>
<!--下面两个对应IDEA中的一个配置Java:SPACE_AROUND_LAMBDA_ARROW,使用insert-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_before_lambda_arrow" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_space_after_lambda_arrow" value="insert"/>
<!--SPACE_WITHIN_EMPTY_ARRAY_INITIALIZER_BRACES-->
<setting id="org.eclipse.jdt.core.formatter.insert_space_between_empty_braces_in_array_initializer"
value="do not insert"/>
<!--Idea -> Wrapping And Braces -> Simple classes in one line -->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_annotation_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_anonymous_type_declaration"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_type_declaration" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_enum_declaration" value="do not insert"/>
<!--Idea -> Wrapping And Braces -> Simple method in one line -->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_method_body" value="do not insert"/>
<!--因为Idea不支持配置,所以设置为 Idea默认值-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_package" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_parameter"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_enum_constant"
value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_enum_constant" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_type_annotation" value="do not insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_label" value="insert"/>
<!--Idea可以通过Wrap Always实现 TODO-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_field" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_method" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_local_variable" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_annotation_on_type" value="insert"/>
<!--Idea -> Wrapping And Braces -> Simple block in one line -> do not select -->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_in_empty_block" value="insert"/>
<!--Idea -> Wrapping And Braces -> try statement -> catch.... (Java:CATCH_ON_NEW_LINE)-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_catch_in_try_statement"
value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_new_line_at_end_of_file_if_missing=<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_at_end_of_file_if_missing" value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_new_line_before_closing_brace_in_array_initializer=Java:ARRAY_INITIALIZER_RBRACE_ON_NEXT_LINE-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_closing_brace_in_array_initializer"
value="do not insert"/>
<!--#org.eclipse.jdt.core.formatter.insert_new_line_after_opening_brace_in_array_initializer=Java:ARRAY_INITIALIZER_LBRACE_ON_NEXT_LINE-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_after_opening_brace_in_array_initializer"
value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_new_line_before_else_in_if_statement=Java:ELSE_ON_NEW_LINE-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_else_in_if_statement" value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_new_line_before_while_in_do_statement=Java:WHILE_ON_NEW_LINE-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_while_in_do_statement"
value="do not insert"/>
<!--org.eclipse.jdt.core.formatter.insert_new_line_before_finally_in_try_statement=Java:FINALLY_ON_NEW_LINE-->
<setting id="org.eclipse.jdt.core.formatter.insert_new_line_before_finally_in_try_statement"
value="do not insert"/>
<!--comment start-->
<setting id="org.eclipse.jdt.core.formatter.comment.line_length" value="120"/>
<!--ENABLE_JAVADOC_FORMATTING-->
<setting id="org.eclipse.jdt.core.formatter.comment.format_javadoc_comments" value="true"/>
<!--org.eclipse.jdt.core.formatter.comment.clear_blank_lines_in_javadoc_comment=<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.comment.clear_blank_lines_in_javadoc_comment" value="false"/>
<!--IDEA无对应设置,所以关闭对block comment的格式化 -->
<setting id="org.eclipse.jdt.core.formatter.comment.format_block_comments" value="false"/>
<setting id="org.eclipse.jdt.core.formatter.comment.clear_blank_lines_in_block_comment" value="false"/>
<setting id="org.eclipse.jdt.core.formatter.comment.new_lines_at_block_boundaries" value="true"/>
<!--org.eclipse.jdt.core.formatter.never_indent_line_comments_on_first_column=Java:KEEP_FIRST_COLUMN_COMMENT-->
<setting id="org.eclipse.jdt.core.formatter.never_indent_line_comments_on_first_column" value="false"/>
<!--org.eclipse.jdt.core.formatter.use_on_off_tags=FORMATTER_TAGS_ENABLED-->
<setting id="org.eclipse.jdt.core.formatter.use_on_off_tags" value="true"/>
<!--org.eclipse.jdt.core.formatter.disabling_tag=FORMATTER_OFF_TAG-->
<setting id="org.eclipse.jdt.core.formatter.disabling_tag" value="@formatter:off"/>
<!--org.eclipse.jdt.core.formatter.enabling_tag=FORMATTER_ON_TAG-->
<setting id="org.eclipse.jdt.core.formatter.enabling_tag" value="@formatter:on"/>
<!--use default do not insert-->
<setting id="org.eclipse.jdt.core.formatter.comment.insert_new_line_for_parameter" value="do not insert"/>
<!--下面的没有IDEA对应项,在代码里面对IDEA中使用默认值即可,LINE_COMMENT_AT_FIRST_COLUMN BLOCK_COMMENT_AT_FIRST_COLUMN设置为false-->
<setting id="org.eclipse.jdt.core.formatter.never_indent_block_comments_on_first_column" value="false"/>
<setting id="org.eclipse.jdt.core.formatter.comment.insert_new_line_before_root_tags" value="insert"/>
<setting id="org.eclipse.jdt.core.formatter.comment.indent_root_tags" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.comment.preserve_white_space_between_code_and_line_comments"
value="false"/>
<setting id="org.eclipse.jdt.core.formatter.format_line_comment_starting_on_first_column" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.comment.format_line_comments" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.comment.format_header" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.comment.new_lines_at_javadoc_boundaries" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.comment.format_source_code" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.comment.format_html" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.join_lines_in_comments" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.comment.indent_parameter_description" value="false"/>
<!--comment end-->
<!--org.eclipse.jdt.core.formatter.blank_lines_after_imports=Java:BLANK_LINES_AFTER_IMPORTS-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_after_imports" value="1"/>
<!--org.eclipse.jdt.core.formatter.blank_lines_before_imports=Java:BLANK_LINES_BEFORE_IMPORTS-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_imports" value="1"/>
<!--org.eclipse.jdt.core.formatter.blank_lines_after_package=Java:BLANK_LINES_AFTER_PACKAGE-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_after_package" value="1"/>
<!--org.eclipse.jdt.core.formatter.blank_lines_between_type_declarations=Java:BLANK_LINES_AROUND_CLASS-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_between_type_declarations" value="1"/>
<!--org.eclipse.jdt.core.formatter.number_of_blank_lines_at_beginning_of_method_body=Java:BLANK_LINES_BEFORE_METHOD_BODY-->
<setting id="org.eclipse.jdt.core.formatter.number_of_blank_lines_at_beginning_of_method_body" value="0"/>
<!--org.eclipse.jdt.core.formatter.blank_lines_before_first_class_body_declaration=Java:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_first_class_body_declaration" value="0"/>
<!--org.eclipse.jdt.core.formatter.blank_lines_before_field=Java:BLANK_LINES_AROUND_FIELD-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_field" value="0"/>
<!--org.eclipse.jdt.core.formatter.blank_lines_before_method=Java:BLANK_LINES_AROUND_METHOD-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_method" value="1"/>
<!--org.eclipse.jdt.core.formatter.blank_lines_before_package=Java:BLANK_LINES_BEFORE_PACKAGE-->
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_package" value="0"/>
<!--下面IDEA没有对应设置,使用对应值即可-->
<setting id="org.eclipse.jdt.core.formatter.align_fields_grouping_blank_lines" value="2147483647"/>
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_new_chunk" value="1"/>
<setting id="org.eclipse.jdt.core.formatter.blank_lines_before_member_type" value="1"/>
<setting id="org.eclipse.jdt.core.formatter.blank_lines_between_import_groups" value="1"/>
<!--org.eclipse.jdt.core.formatter.indentation.size=Java:IndentOptions:INDENT_SIZE-->
<setting id="org.eclipse.jdt.core.formatter.indentation.size" value="4"/>
<!--org.eclipse.jdt.core.formatter.continuation_indentation=Java:IndentOptions:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.continuation_indentation" value="1"/>
<!--org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_type_header=Java:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_type_header" value="true"/>
<!--org.eclipse.jdt.core.formatter.use_tabs_only_for_leading_indentations=Java:IndentOptions:SMART_TABS-->
<setting id="org.eclipse.jdt.core.formatter.use_tabs_only_for_leading_indentations" value="false"/>
<!--org.eclipse.jdt.core.formatter.indent_switchstatements_compare_to_switch=Java:INDENT_CASE_FROM_SWITCH-->
<setting id="org.eclipse.jdt.core.formatter.indent_switchstatements_compare_to_switch" value="true"/>
<!--KEEP_INDENTS_ON_EMPTY_LINES-->
<setting id="org.eclipse.jdt.core.formatter.indent_empty_lines" value="false"/>
<!--org.eclipse.jdt.core.formatter.tabulation.size=Java:IndentOptions:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.tabulation.size" value="4"/>
<!--Java:IndentOptions:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.tabulation.char" value="space"/>
<!--下面IDEA没有对应设置,使用对应值即可-->
<setting id="org.eclipse.jdt.core.formatter.indent_statements_compare_to_block" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_annotation_declaration_header"
value="true"/>
<setting id="org.eclipse.jdt.core.formatter.indent_switchstatements_compare_to_cases" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.continuation_indentation_for_array_initializer" value="1"/>
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_enum_declaration_header"
value="true"/>
<setting id="org.eclipse.jdt.core.formatter.indent_breaks_compare_to_cases" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.indent_statements_compare_to_body" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.indent_body_declarations_compare_to_enum_constant_header"
value="true"/>
<!--Java:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_method_invocation" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_selector_in_method_invocation" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_assignment" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_superinterfaces_in_type_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_binary_expression" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_throws_clause_in_method_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_parameters_in_method_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_resources_in_try" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_annotation" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_conditional_expression" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_expressions_in_array_initializer" value="16"/>
<!--下面没有对应的IDEA设置,Eclipse先使用对应值-->
<setting id="org.eclipse.jdt.core.formatter.alignment_for_enum_constants" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_enum_constant" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_parameterized_type_references" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_union_type_in_multicatch" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_explicit_constructor_call" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_parameters_in_constructor_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_type_parameters" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_throws_clause_in_constructor_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_allocation_expression" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_method_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_superclass_in_type_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_superinterfaces_in_enum_declaration" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_compact_if" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_type_arguments" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_arguments_in_qualified_allocation_expression"
value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_multiple_fields" value="16"/>
<setting id="org.eclipse.jdt.core.formatter.alignment_for_expressions_in_for_loop_header" value="16"/>
<!--IDEA默认配置在同一行,Eclipse使用对应值即可-->
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_for_statment" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_method_invocation" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_switch_statement" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_enum_constant_declaration"
value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_if_while_statement" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_catch_clause" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_annotation" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_try_clause" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_method_delcaration" value="common_lines"/>
<setting id="org.eclipse.jdt.core.formatter.parentheses_positions_in_lambda_declaration" value="common_lines"/>
<!--Java:BINARY_OPERATION_SIGN_ON_NEXT_LINE-->
<setting id="org.eclipse.jdt.core.formatter.wrap_before_binary_operator" value="true"/>
<!--ASSIGNMENT_WRAP 需要设置为 WRAP_AS_NEEDED WRAP_AS_NEEDED . Add in jdt.core-3.12,it's not work in previous version -->
<setting id="org.eclipse.jdt.core.formatter.wrap_before_assignment_operator" value="false"/>
<!--IDEA无配置项,Eclipse使用对应值即可-->
<setting id="org.eclipse.jdt.core.formatter.wrap_before_or_operator_multicatch" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.wrap_before_conditional_operator" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.wrap_outer_expressions_when_nested" value="true"/>
<setting id="org.eclipse.jdt.core.formatter.keep_else_statement_on_same_line" value="false"/>
<setting id="org.eclipse.jdt.core.formatter.put_empty_statement_on_new_line" value="false"/>
<setting id="org.eclipse.jdt.core.formatter.format_guardian_clause_on_one_line" value="false"/>
<setting id="org.eclipse.jdt.core.formatter.keep_empty_array_initializer_on_one_line" value="false"/>
<!--org.eclipse.jdt.core.formatter.keep_then_statement_on_same_line=Java:KEEP_CONTROL_STATEMENT_IN_ONE_LINE-->
<setting id="org.eclipse.jdt.core.formatter.keep_then_statement_on_same_line" value="false"/>
<!--org.eclipse.jdt.core.formatter.compact_else_if=Java:SPECIAL_ELSE_IF_TREATMENT-->
<setting id="org.eclipse.jdt.core.formatter.compact_else_if" value="true"/>
<!--Java:ALIGN_GROUP_FIELD_DECLARATIONS-->
<setting id="org.eclipse.jdt.core.formatter.align_type_members_on_columns" value="false"/>
<!--Java:<Programmatic>-->
<setting id="org.eclipse.jdt.core.formatter.number_of_empty_lines_to_preserve" value="1"/>
<setting id="org.eclipse.jdt.core.formatter.join_wrapped_lines" value="true"/>
<!--统一为end_of_lint,IDEA默认一致-->
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_method_declaration" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_anonymous_type_declaration" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_block" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_constructor_declaration" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_lambda_body" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_enum_declaration" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_block_in_case" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_annotation_type_declaration"
value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_switch" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_array_initializer" value="end_of_line"/>
<!-- <setting id="org.eclipse.jdt.core.compiler.source" value="1.8"/>
<setting id="org.eclipse.jdt.core.compiler.compliance" value="1.8"/>
<setting id="org.eclipse.jdt.core.compiler.codegen.targetPlatform" value="1.8"/>
<setting id="org.eclipse.jdt.core.compiler.problem.enumIdentifier" value="error"/>
<setting id="org.eclipse.jdt.core.compiler.problem.assertIdentifier" value="error"/>
<setting id="org.eclipse.jdt.core.compiler.codegen.inlineJsrBytecode" value="enabled"/>
-->
<!--Java:KEEP_SIMPLE_BLOCKS_IN_ONE_LINE-->
<setting id="org.eclipse.jdt.core.formatter.keep_imple_if_on_one_line" value="false"/>
<!--Java:CLASS_BRACE_STYLE,统一使用end_of_line TODO-->
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_enum_constant" value="end_of_line"/>
<setting id="org.eclipse.jdt.core.formatter.brace_position_for_type_declaration" value="end_of_line"/>
<!--org.eclipse.jdt.core.formatter.lineSplit=RIGHT_MARGIN-->
<setting id="org.eclipse.jdt.core.formatter.lineSplit" value="120"/>
</profile>
</profiles>打开Window->Preferences->Java->Code Style->Formatter
点击import 插入eclipse-codestyle
(eclipse-codetemplate.xml)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30<templates><template autoinsert="true" context="gettercomment_context" deleted="false" description="Comment for getter method" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.gettercomment" name="gettercomment">/**
* @return the ${bare_field_name}
*/</template><template autoinsert="true" context="settercomment_context" deleted="false" description="Comment for setter method" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.settercomment" name="settercomment">/**
* @param ${param} the ${bare_field_name} to set
*/</template><template autoinsert="true" context="constructorcomment_context" deleted="false" description="Comment for created constructors" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.constructorcomment" name="constructorcomment">/**
* ${tags}
*/</template><template autoinsert="true" context="filecomment_context" deleted="false" description="Comment for created Java files" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.filecomment" name="filecomment"/><template autoinsert="true" context="typecomment_context" deleted="false" description="Comment for created types" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.typecomment" name="typecomment">/**
* @author ${user}
* @date ${currentDate:date('YYYY/MM/dd')}
*/</template><template autoinsert="true" context="fieldcomment_context" deleted="false" description="Comment for fields" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.fieldcomment" name="fieldcomment">/**
*
*/</template><template autoinsert="true" context="methodcomment_context" deleted="false" description="Comment for non-overriding methods" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.methodcomment" name="methodcomment">/**
* ${tags}
*/</template><template autoinsert="true" context="overridecomment_context" deleted="false" description="Comment for overriding methods" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.overridecomment" name="overridecomment">/* (non-Javadoc)
* ${see_to_overridden}
*/</template><template autoinsert="true" context="delegatecomment_context" deleted="false" description="Comment for delegate methods" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.delegatecomment" name="delegatecomment">/**
* ${tags}
* ${see_to_target}
*/</template><template autoinsert="true" context="newtype_context" deleted="false" description="Newly created files" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.newtype" name="newtype">${filecomment}
${package_declaration}
${typecomment}
${type_declaration}</template><template autoinsert="true" context="classbody_context" deleted="false" description="Code in new class type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.classbody" name="classbody">
</template><template autoinsert="true" context="interfacebody_context" deleted="false" description="Code in new interface type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.interfacebody" name="interfacebody">
</template><template autoinsert="true" context="enumbody_context" deleted="false" description="Code in new enum type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.enumbody" name="enumbody">
</template><template autoinsert="true" context="annotationbody_context" deleted="false" description="Code in new annotation type bodies" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.annotationbody" name="annotationbody">
</template><template autoinsert="true" context="catchblock_context" deleted="false" description="Code in new catch blocks" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.catchblock" name="catchblock">// ${todo} Auto-generated catch block
${exception_var}.printStackTrace();</template><template autoinsert="true" context="methodbody_context" deleted="false" description="Code in created method stubs" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.methodbody" name="methodbody">// ${todo} Auto-generated method stub
${body_statement}</template><template autoinsert="true" context="constructorbody_context" deleted="false" description="Code in created constructor stubs" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.constructorbody" name="constructorbody">${body_statement}
// ${todo} Auto-generated constructor stub</template><template autoinsert="true" context="getterbody_context" deleted="false" description="Code in created getters" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.getterbody" name="getterbody">return ${field};</template><template autoinsert="true" context="setterbody_context" deleted="false" description="Code in created setters" enabled="true" id="org.eclipse.jdt.ui.text.codetemplates.setterbody" name="setterbody">${field} = ${param};</template></templates>设置代码格式化的实现时间(一般为当保存的时候自动格式化):
进入eclipse菜单: Window > Preferences > Java > Editor > Save Actions,勾选上Perform the selected actions on save 下的Format source code,并选择 Format all lines,勾选上Organize imports,点击右下角的Apply 使其生效。
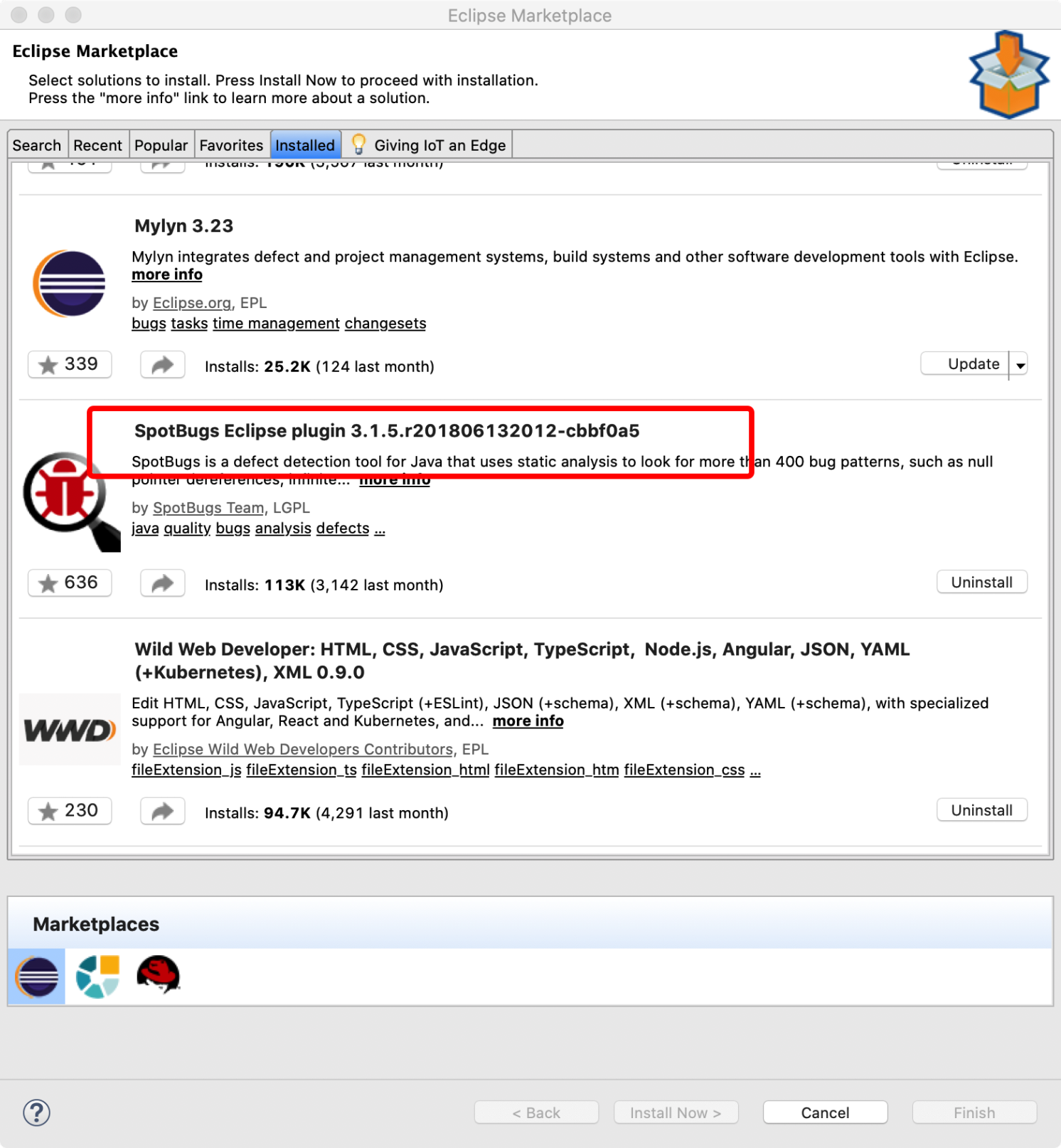
代码质量检查 - Findbugs
安装spotbugs
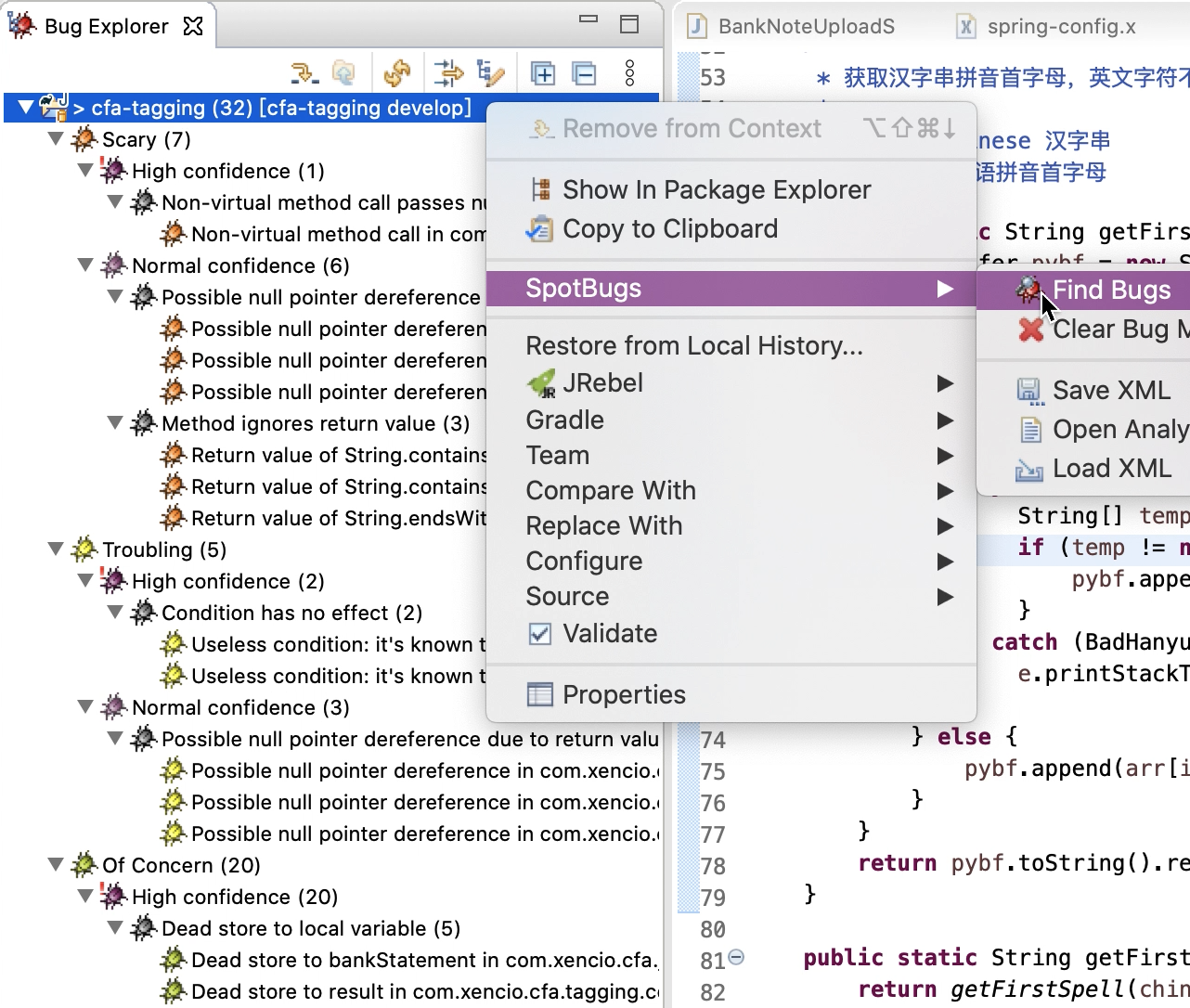
代码修复
Centos7上安装Solr-8.4.1
环境
1.操作系统centos7 64位。
2.需要安装jdk1.8及以上版本。
3.使用solr内置的jetty容器部署solr服务。
现状
1.目前后台使用solr不支持权限。
2.目前只需部署单节点即可。
下载
- 安装包:solr-8.4.1.tgz
- 下载地址:https://archive.apache.org/dist/lucene/solr/8.4.1/solr-8.4.1.tgz
安装
在/usr/local/下创建solr目录,并赋权限。
1 | [root@admin /]# cd /usr/local/ |
进入solr文件夹,上传压缩包solr-8.4.1.tgz,并解压得到solr-8.4.1文件夹。
1 | [root@admin local]# cd solr/ |
启动solr
进入解压后的solr-8.4.1/bin/目录,solr这个脚本用于启动、停止、查看solr运行状态等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19./solr start -p 端口 -force 启动
./solr stop -all 关闭
./solr status 查看状态
[root@admin solr]# cd solr-8.4.1/bin/
[root@admin bin]# ls
init.d install_solr_service.sh oom_solr.sh post solr solr.cmd solr.in.cmd solr.in.sh
[root@admin bin]# ./solr start -p 8983 -force
Started Solr server on port 8983 (pid=7834). Happy searching!
注意:
如果linux系统中缺少lsof组件,在启动solr时将报如下提示:
*** [WARN] *** Your open file limit is currently 1024.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
*** [WARN] *** Your Max Processes Limit is currently 3795.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
NOTE: Please install lsof as this script needs it to determine if Solr is listening on port 8983.
解决方案: 安装 lsof 组件即可
[root@admin bin]# yum -y install lsof设置防火墙开启8983端口开放远程访问
1
2
3
4[root@admin bin]# firewall-cmd --zone=public --add-port=8983/tcp --permanent
success
[root@admin bin]# firewall-cmd --reload
success浏览器访问管理页面 http://192.168.159.130:8983/solr
创建内核
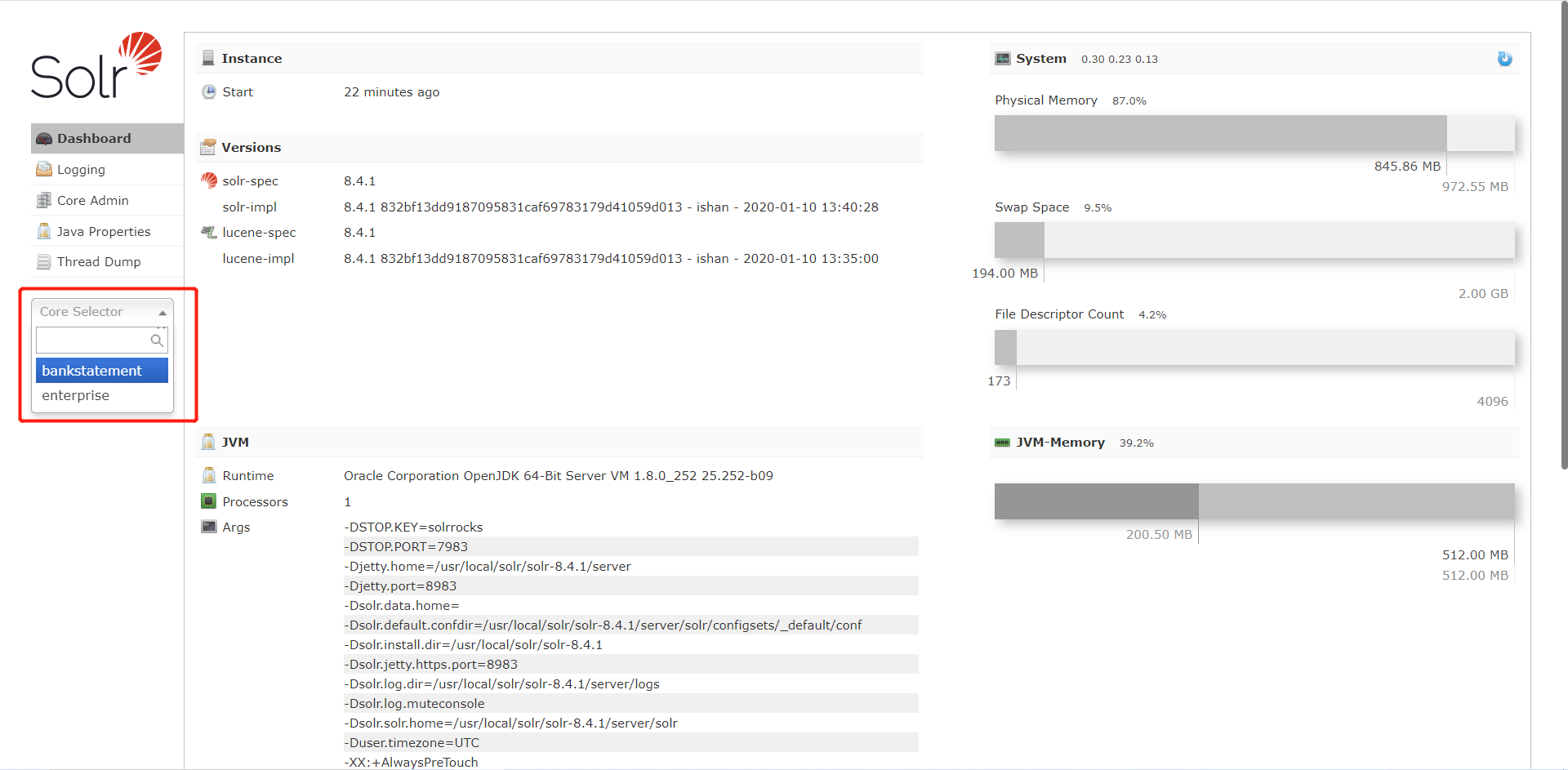
目前后台需创建两个内核:bankstatement用于对账单的索引、enterprise用于对手方企业的索引。1
2
3
4
5
6
7
8[root@admin bin]# ./solr create -c bankstatement -force
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin/solr config -c bankstatement -p 8983 -action set-user-property -property update.autoCreateFields -value false
Created new core 'bankstatement'
[root@admin bin]# ./solr create -c enterprise -force
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin/solr config -c enterprise -p 8983 -action set-user-property -property update.autoCreateFields -value false
Created new core 'enterprise'
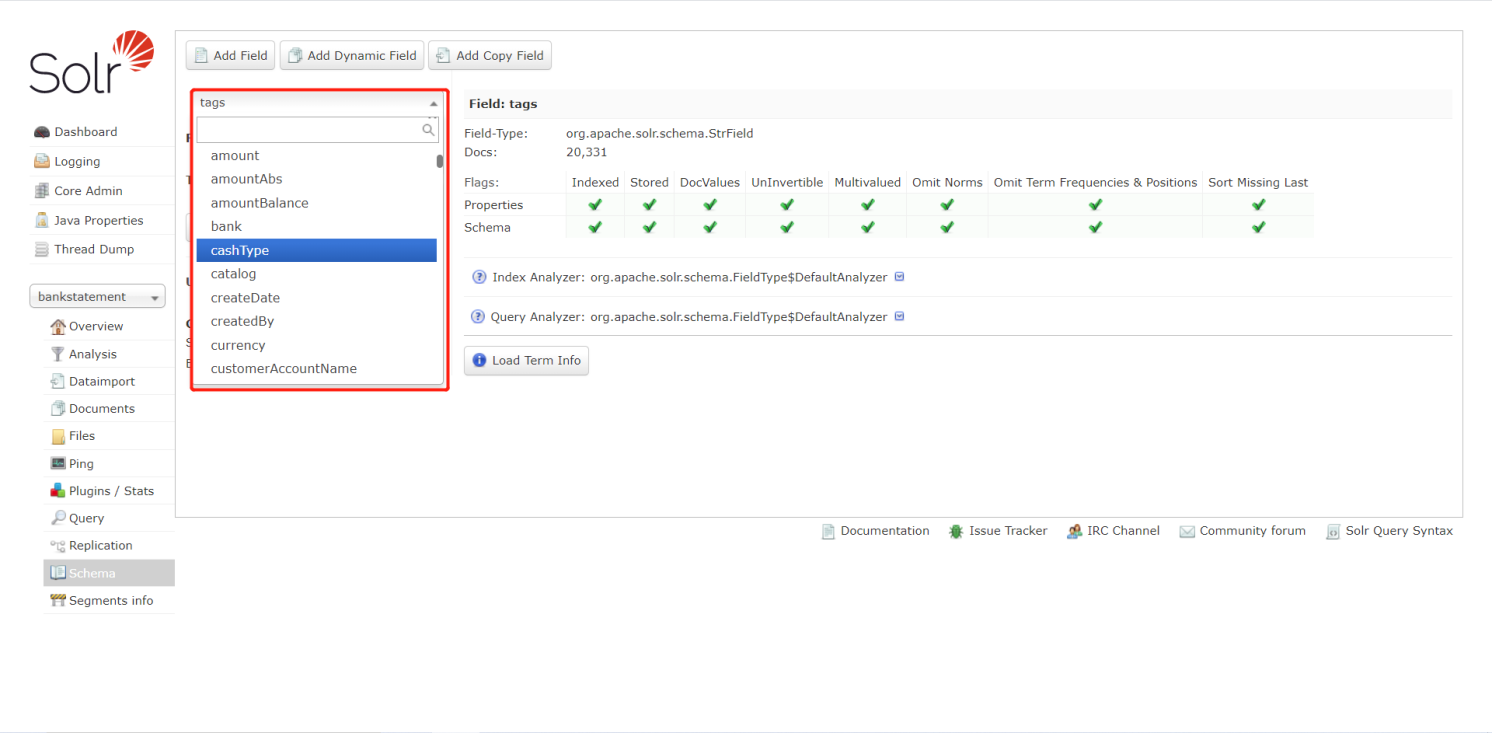
配置字段
在内核上创建字段、以及配置字段属性。
- 内核bankstatement:发送post请求:http://192.168.159.130:8983/solr/bankstatement/schema
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213Content-Type:application/json
请求体:
{
"add-field":[
{
"name":"leId",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"leAccountName",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"leAccountNo",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"trxFlag",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"accountingDateId",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"trxDate",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"amount",
"type":"pdouble",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"amountAbs",
"type":"pdouble",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"currency",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"amountBalance",
"type":"pdouble",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"cashType",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"customerAccountName",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"customerAccountNo",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"userMemo",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"bank",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"createDate",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"createdBy",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"yearId",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"quarterId",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"monthId",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"weekId",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"dayId",
"type":"pint",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"catalog",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"tags",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":true,
"required":false
}
],
"add-dynamic-field":{
"name":"muti_catalog_*",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
}
}
返回:表示成功
{
"responseHeader":{
"status":0,
"QTime":22606
}
}
- 内核enterprise:
发送post请求:http://192.168.159.130:8983/solr/enterprise/schema1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29Content-Type:application/json
请求体:
{
"add-field":[
{
"name":"name",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":false,
"required":false
},
{
"name":"tags",
"type":"string",
"indexed":true,
"stored":true,
"multiValued":true,
"required":false
}
]
}
返回:表示成功
{
"responseHeader":{
"status":0,
"QTime":12265
}
}
企业级搜索应用服务器Solr(一)
初识Solr
这几天新接触了一个Apache开源的搜索服务器Solr。
介绍
Solr是一个独立的企业级搜索应用服务器,它对外提供 API 接口。用户可以通过HTTP请求向Solr服务器提出插入数据和查找请求。交互数据主要是 JSON,但也可以是 XML、CSV 或其他格式。
Solr的部署分两种:单节点/SolrCloud集群。
Solr和一般的NoSQL 数据库一样,它是一种非关系数据存储和处理技术。存储结构是文档,文档都是扁平结构的,文档之间不存在相互依赖关系。
为什么要solr:
- solr是将整个索引操作功能封装好了的搜索引擎系统(企业级搜索引擎产品)。
- solr可以部署到单独的服务器上(WEB服务),它可以提供服务,我们的业务系统就只要发送请求,接收响应即 可,降低了业务系统的负载。
- solr部署在专门的服务器上,它的索引库就不会受业务系统服务器存储空间的限制。
- solr支持分布式集群,索引服务的容量和能力可以线性扩展。
windows下安装Solr
安装 1.8+ 版本jdk。
下载solr-8.4.1.zip,并解压到自定义路径下。http://apache.cs.utah.edu/lucene/solr/8.4.1/solr-8.4.1.zip
使用bin\solr.cmd,启动和停止 Solr、创建核心和集合、检查系统的状态…
这里只介绍启动单个Solr节点。
solr 启动、停止、重启命令
solr.cmd start -p 端口号
solr.cmd stop -all
solr.cmd restart -p 端口号
启动 Solr。默认端口:8983。
检查Solr是否正在运行。
访问管理控制台:http://localhost:8983/solr/
需要创建一个core才能进行索引和搜索。
接下来就可以把文档存放到这个core上了。
core我的理解是:一个Solr 服务器实例,在实例上可以进行数据的CRUD了。这个数据一般存放类型相同的一类文档。我这边干脆就取名为user,准备放user一类的文档数据了。
一个Solr服务可以有多个core。
core配置文件介绍: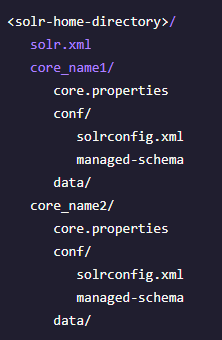
- solr.xml:为Solr 服务器实例指定配置选项。
- 每个 Solr 核心:
- core.properties:为每个核心定义特定的属性,例如其名称、模式的位置以及其他参数。
- solrconfig.xml:控制高级行为。主要定义了Solr的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置。
- managed-schema:描述将要求 Solr 索引的文档。为文档量身配置各种规则。这个配置文件非常重要。可以定义字段如何索引,字段类型有多少filter chain分词器、过滤器…以及其他很重要的配置。修改配置可以通过http请求api修改。
- data/:索引、日志文件等。
字段、字段类型等配置说明
字段定义

name:该字段的名称。
type:该fieldType字段的名称,必填。
indexed:如果为 true,则可以在查询中使用该字段的值来检索匹配的文档。默认true。
…
字段类型定义

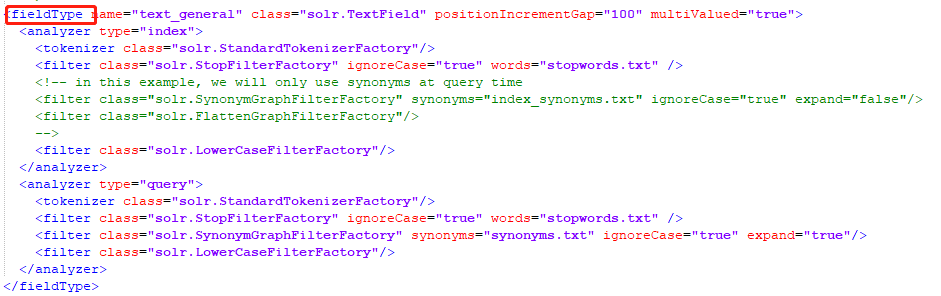
name:fieldType 的名称
class:用于存储和索引此类型数据的类名
索引(indexed):如果为 true,则可以在查询中使用该字段的值来检索匹配的文档。默认true
存储(stored): 如果为 true,则字段的实际值可以通过查询来检索。默认true
docValues:如果为 true,则该字段的值将被放入一个面向列的 DocValues 结构中。
…
Schema API 操作managed-schema
使用 HTTP API 来管理这些配置
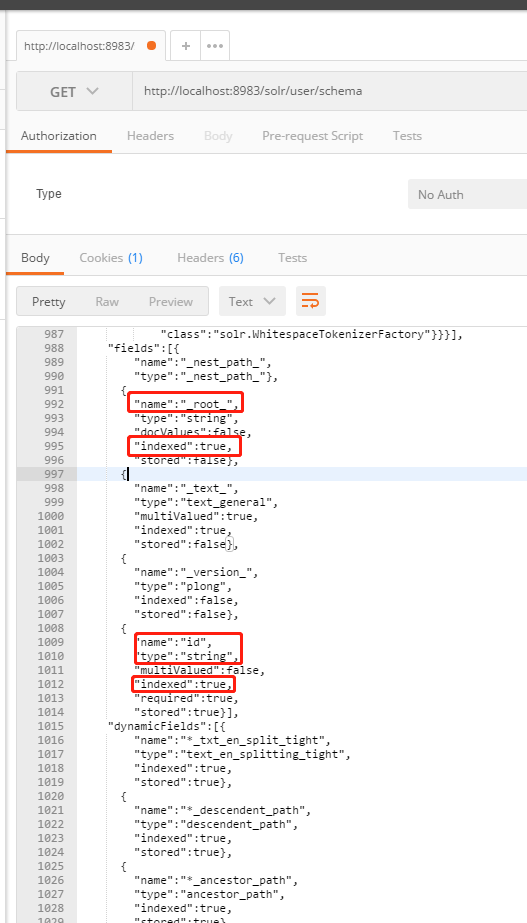
可以看到uesr这个core中,申明的字段和索引情况。
add-field
刚定义的字段,在文档中生成了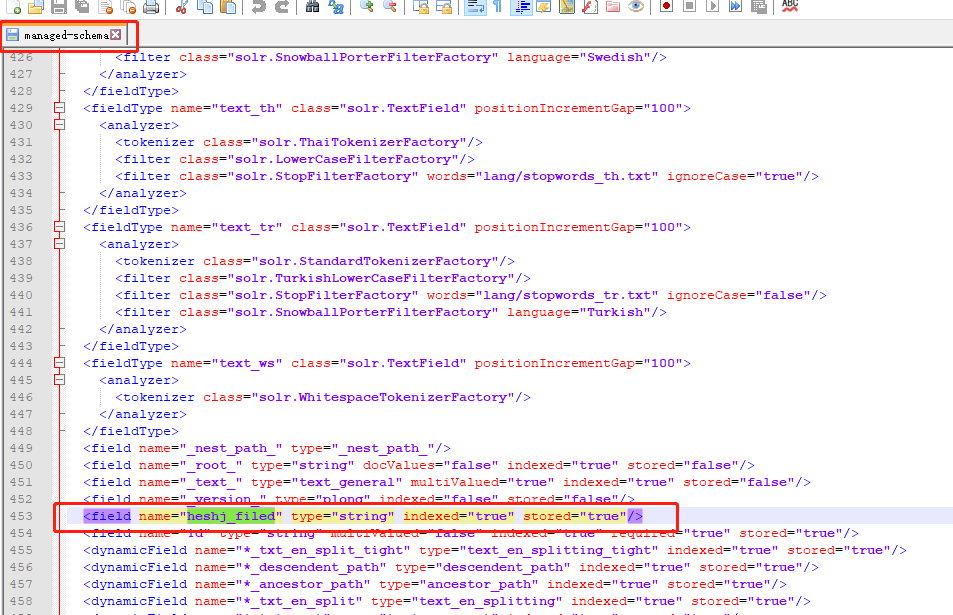
Solr分析器、标记器和过滤器

标记器:Tokenizer 的工作是将文本流分解为令牌,其中每个令牌(通常)是文本中字符的子序列。分析器知道它配置的字段,但 tokenizer 不是。Tokenizers 从字符流(Reader)中读取并生成一系列令牌对象(TokenStream)。
过滤器:过滤器的工作通常比 tokenizer 更容易,因为在大多数情况下,过滤器会依次查看流中的每个标记,并决定是否将其传递、替换或丢弃。
去管理页面,感受下分析器、标记器和过滤器是如何链式运作的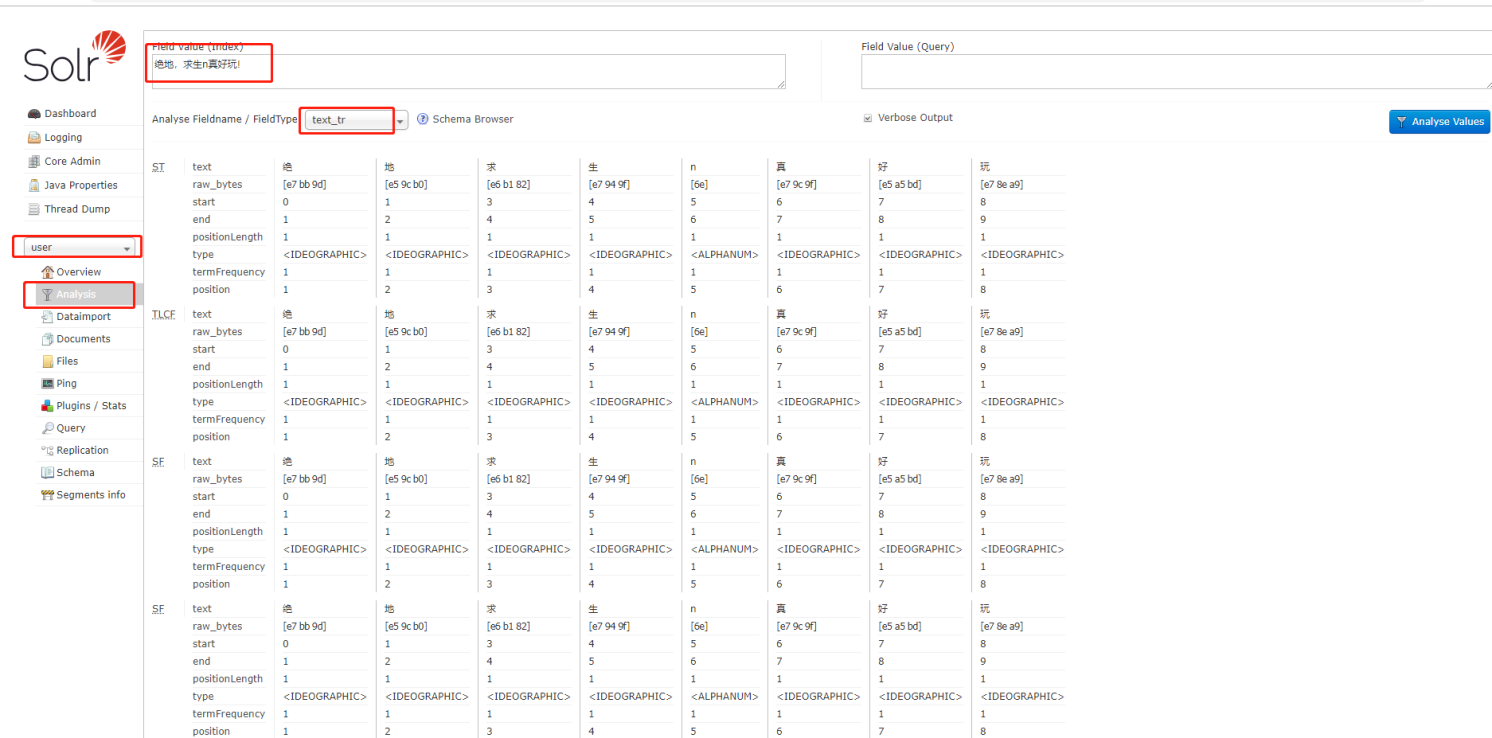
上传数据
Solr 可以接受来自许多不同来源的数据,包括 XML 文件、JSON文件、逗号分隔值(CSV)文件、从数据库表格中提取的数据以及常用文件格式(如 Microsoft Word 或 PDF)中的文件。
介绍3种方式,第一种方式用来上传数据库数据,后两种方式比较常见。
①Solr DataImportHandler
②HTTP 请求到 Solr 服务器来上传 XML 文件、json文件。XML格式的更新请求可以使用 Content-type: application/xml 或者 Content-type: text/xml 作为 XML 消息发送到更新处理程序;JSON 格式的更新请求可以使用 Content-Type: application/json 或 Content-Type: text/json 发送到 Solr 的 /update 处理程序。
③编写自定义 Java 应用程序以通过 SolrJ来获取数据(推荐)
前期准备: 添加field,与数据库表的字段对应起来
这是我们的数据源,将前5个作为字段传输。这里准备了435510 条数据
先确认。这5个字段,managed-schema没被定义过
使用Postman 批量添加field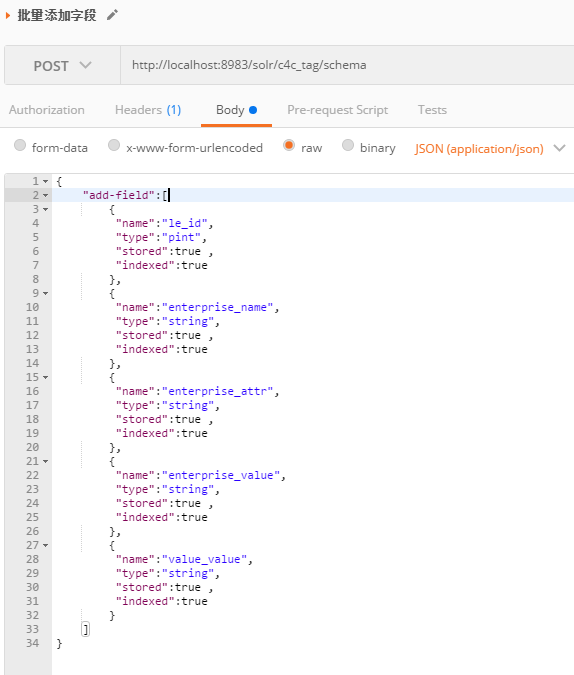
Solr DataImportHandler来上传数据库数据
DataImportHandler提供一种可配置的方式向Solr导入数据,可以全量导入,也可以增量导入,还可声明式提供可配置的任务调度,让数据定时从关系型数据库中更新数据到Solr服务器。详见
https://blog.csdn.net/qq_41674409/article/details/85143606
下载 mysql-connector-java-5.1.40.jar(版本不要太高,会不兼容) 添加到solr-8.4.1\server\solr-webapp\webapp\WEB-INF\lib 下。
将solr-dataimporthandler-8.4.1.jar 、solr-dataimporthandler-extras-8.4.1.jar 从 solr-8.4.1\dist 复制到solr-8.4.1\server\solr-webapp\webapp\WEB-INF\lib 下。
修改 solrconfig.xml 添加 dataImport 请求资源映射。添加在1
<config></config>

\solr-8.4.1\server\solr\user\conf目录下创建 data-config.xml,配置访问数据库的用户名、密码、查询语句,column对应数据库中字段、name对应solr的schema.xml中字段。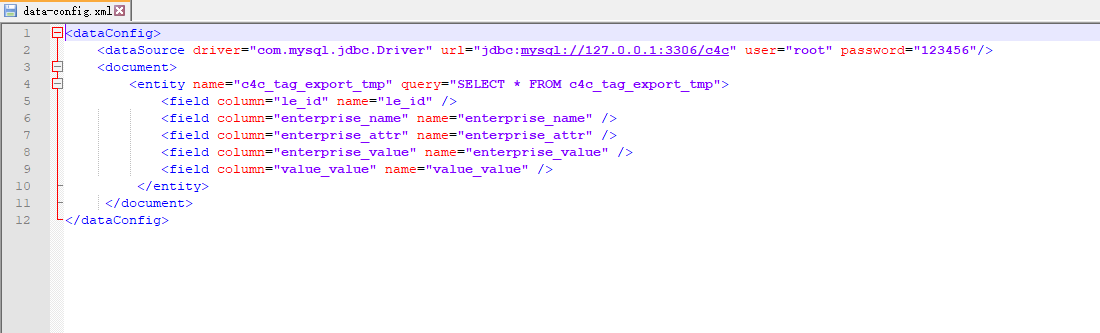
重启Solr: solr restart -p 8983
导入数据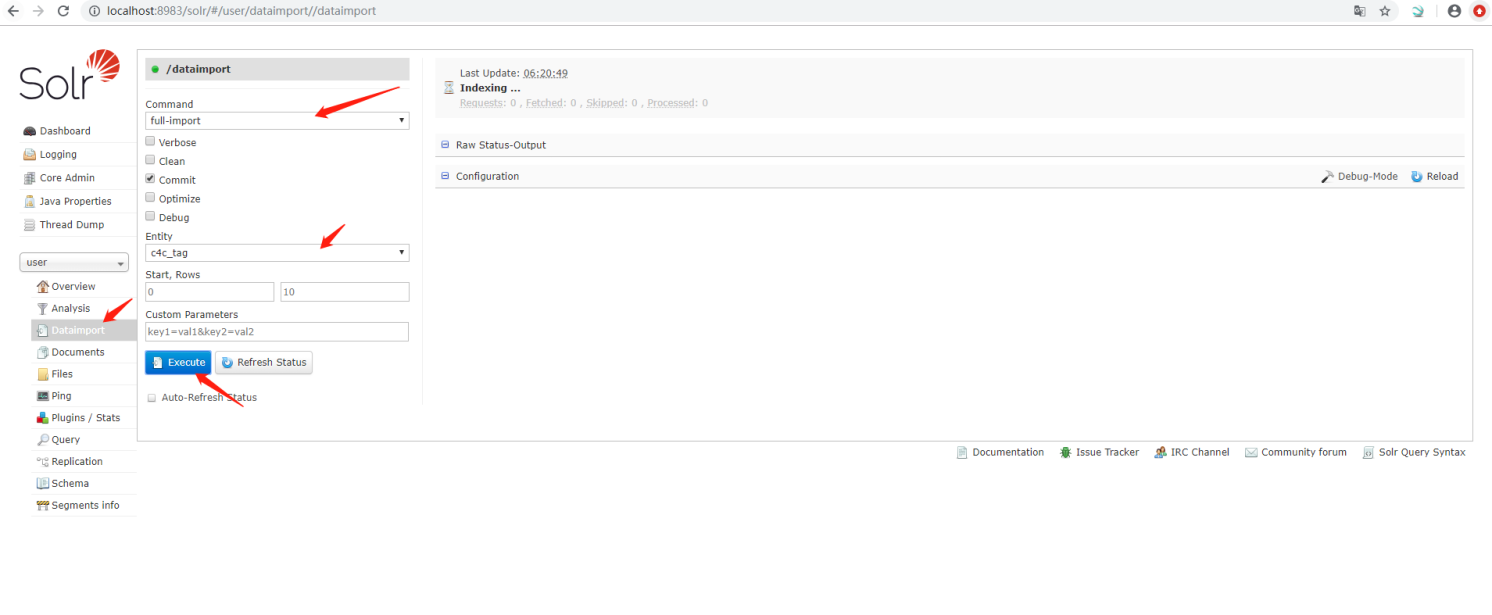
查看数据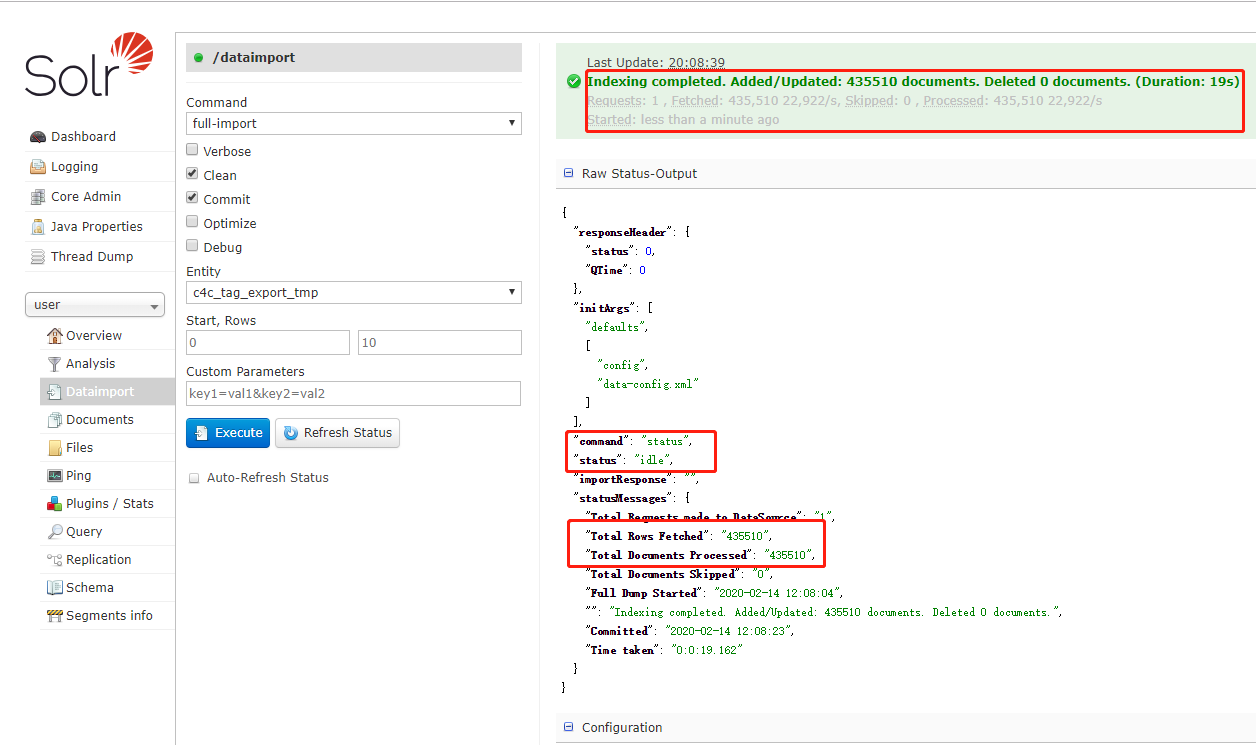
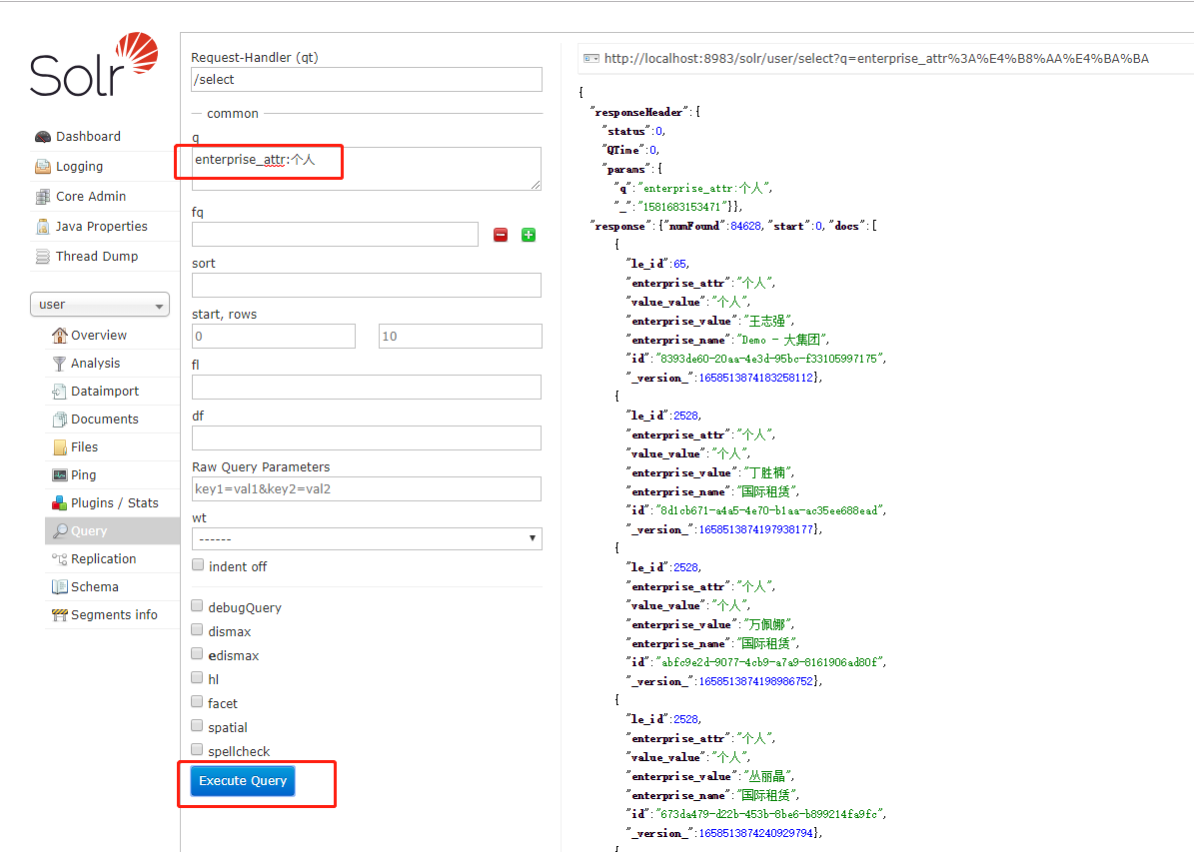
HTTP 请求到 Solr 服务器来上传 XML 文件
准备好满足条件的xml文件,格式为: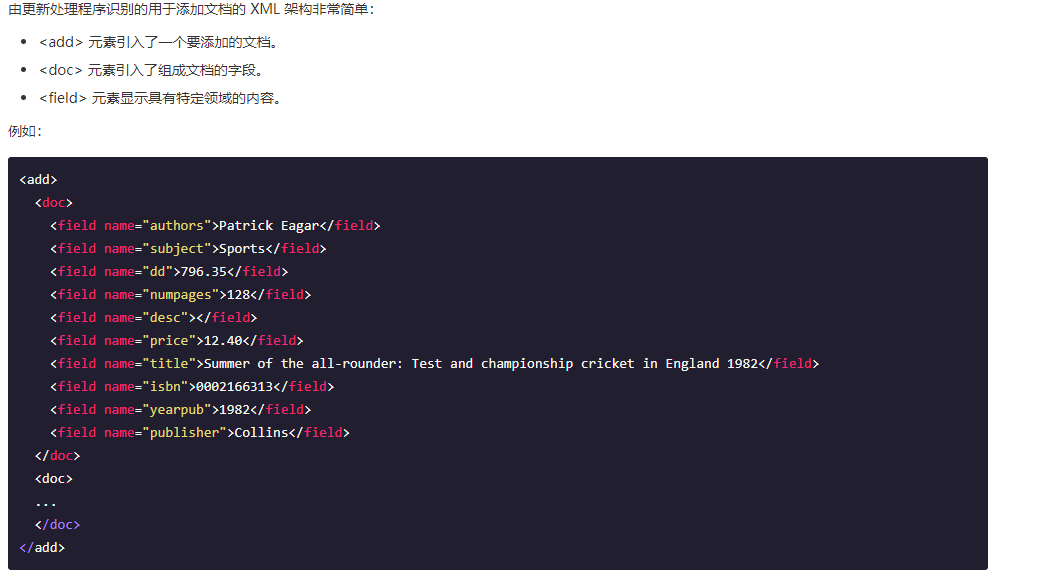
新开一个core,并配置field。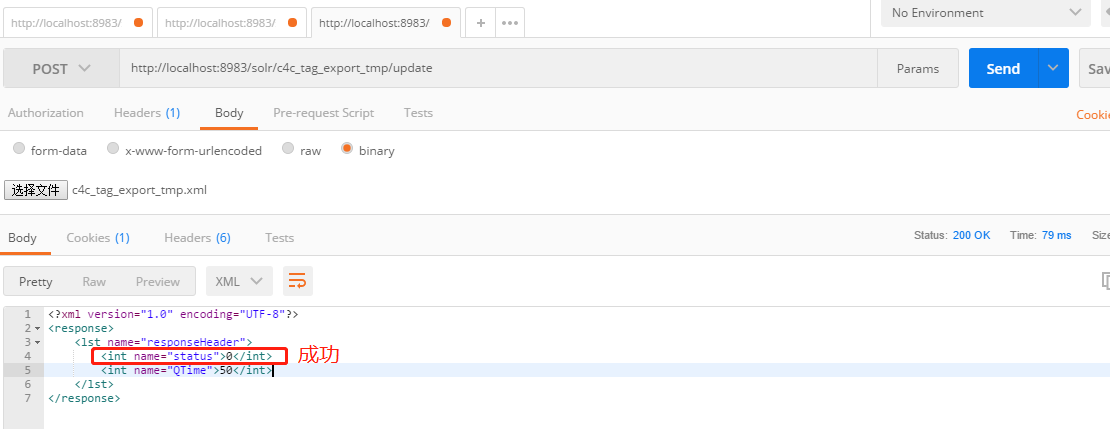
查看数据
编写自定义 Java 应用程序以通过 SolrJ来获取数据
SolrJ导入,放在下面SolrJ模块。
Solr搜索
Solr搜索的工作流程
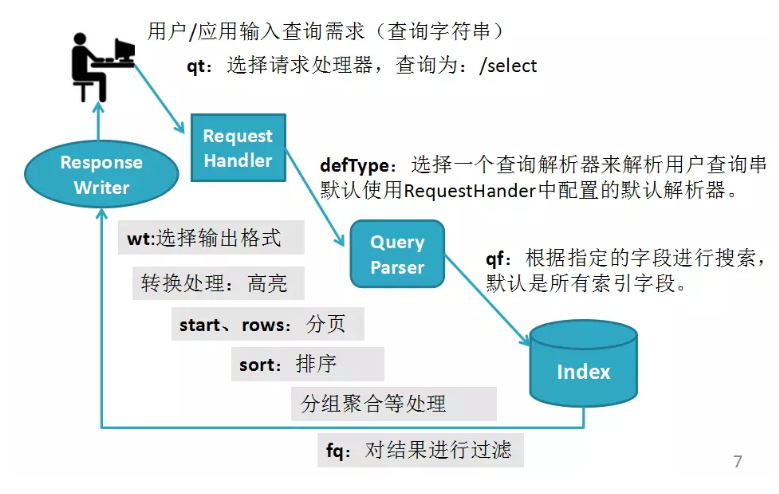
补充:下列这些情况,建议该字段配置docValues属性,提高性能。
需要聚合的字段,包括sort,agg,group,facet等 。
需要提供函数查询的字段。
需要高亮的字段。
通用查询参数
defType 参数
defType 参数指定 Solr 应该用来处理请求中的主查询参数(q)的查询解析器。1
defType=dismax
Solr中提供了三种解析器供选择:
lucene: solr的Standard Query Parser 标准查询解析器(默认)
dismax: DisMax Query Parser
edismax: Extended DisMax Query Parser (eDismax)sort 参数
sort 参数按升序 (asc) 或降序 (desc) 顺序排列搜索结果。1
sort=<field name><direction>,<field name><direction>],…
start 参数
分页查询的起始行号,默认为0;1
start=0
rows 参数
将查询的结果分页,返回最大文档数目。默认值是10。1
rows=20
fq(Filter Query)参数
fq 参数定义了一个查询,可以用来限制可以返回的文档的超集,而不影响 score。这对于加快复杂查询非常有用,因为指定的查询 fq 是独立于主查询而被缓存的。当以后的查询使用相同的过滤器时,会有一个缓存命中,过滤器结果从缓存中快速返回。
fq的传参说明:
在下面的例子中,只有流行度大于10并且段落为0的文档才会匹配。
可以一次传传多个fq:1
fq=popularity:[10 TO *]&fq=section:0
也可将多个过滤条件组合在一个fq:
1
fq=+popularity:[10 TO *] +section:0
每个过滤器查询的文档集都是独立缓存的,几个fq就缓存几个过滤结果集。
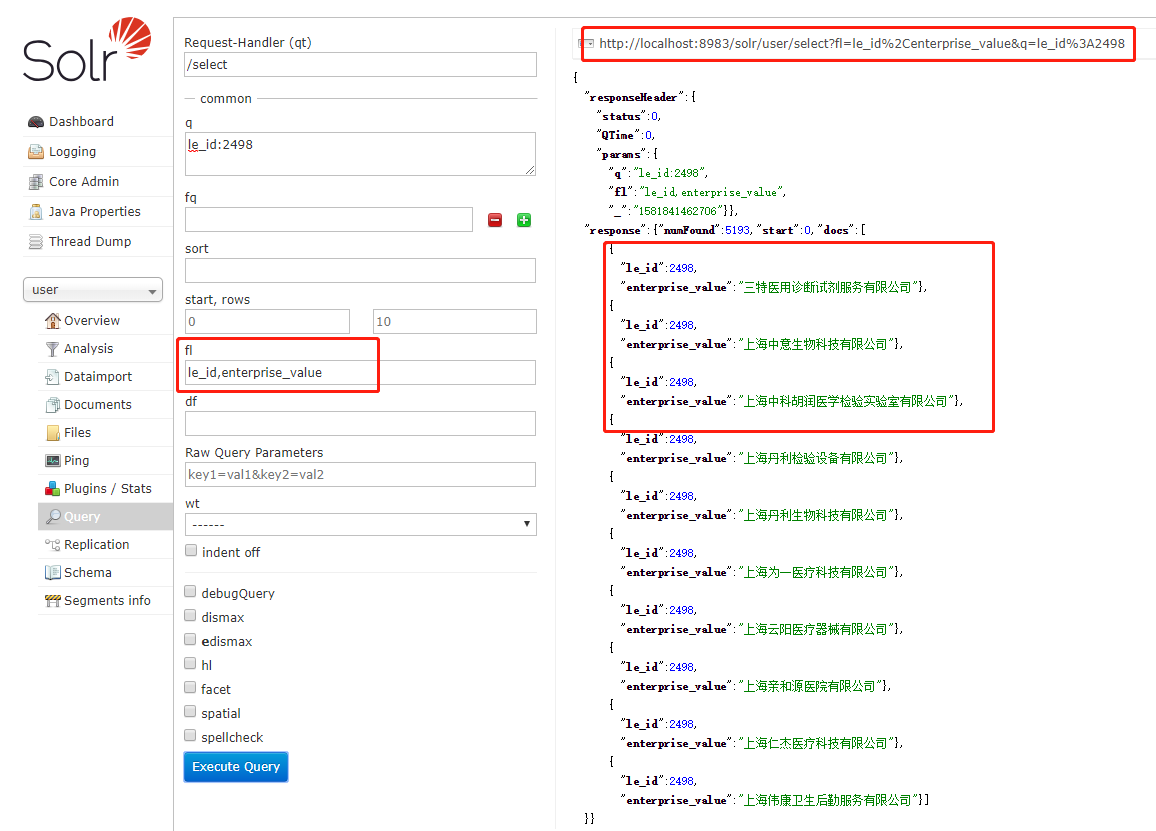
fl(Field List)参数
该 fl 参数将查询响应中包含的信息限制在指定的字段列表中。这些字段必须是 stored=”true” 或 docValues=”true”。
字段列表可以指定为空格分隔或逗号分隔的字段名称列表。
通配符 * 选择文档中的所有字段,它们是 stored=”true”、docValues=”true” 和 useDocValuesAsStored=”true”。
还可以添加伪字段(pseudo-fields)、函数和变换器。
示例:
函数与 fl:
可以为结果中的每个文档计算函数,并将其作为伪字段(pseudo-field)返回:1
fl=id,title,product(price,popularity)
文件变换器与 fl:
文档变换器可以用来修改查询结果中每个文档返回的信息:1
fl=id,title,[explain]
字段名称别名:
可以通过使用 “displayName” 前缀来更改对字段、函数或转换器的响应中使用的键。例如:1
l=id,sales_price:price,secret_sauce:prod(price,popularity),why_score:[explain style=nl]
debug 参数
用于指定在结果中返回调试信息。- timeAllowed 参数
限定查询在多少毫秒内返回,如果到时间了还未执行完成,则直接返回部分结果。 - wt 参数
指定响应的内容格式:json、xml、csv…… SearchHandler根据它选择ResponseWriter。默认JSON 将作为响应的格式返回。 - cache 参数
设置是否对查询结果、过滤查询的结果进行缓存。默认是都会被缓存的。如果不需要缓存明确设置 cache=false。
…
查询解析器
- 标准查询解析器
- DisMax 查询解析器
- 扩展的 DisMax 查询解析器
- 其他解析器
查询解析器插件是 QParserPlugin 的所有子类。可自定义扩展自己的查询分析器。
标准查询解析器
Solr 的标准查询解析器(Query Parser)也被称为 “lucene” 解析器。
标准查询解析器的关键优势在于它支持强大且相当直观的语法,允许您创建各种结构化查询。最大的缺点是它不容忍出现语法错误,与 DisMax 查询解析器相比, DisMax 查询解析器的设计目的是尽可能地减少抛出错误。
参数
q
使用标准查询语法定义查询。必须项。
……
响应
我们通过Solr Admin页面-Query来看看吧。内核user上,有我们之前存入的大量数据。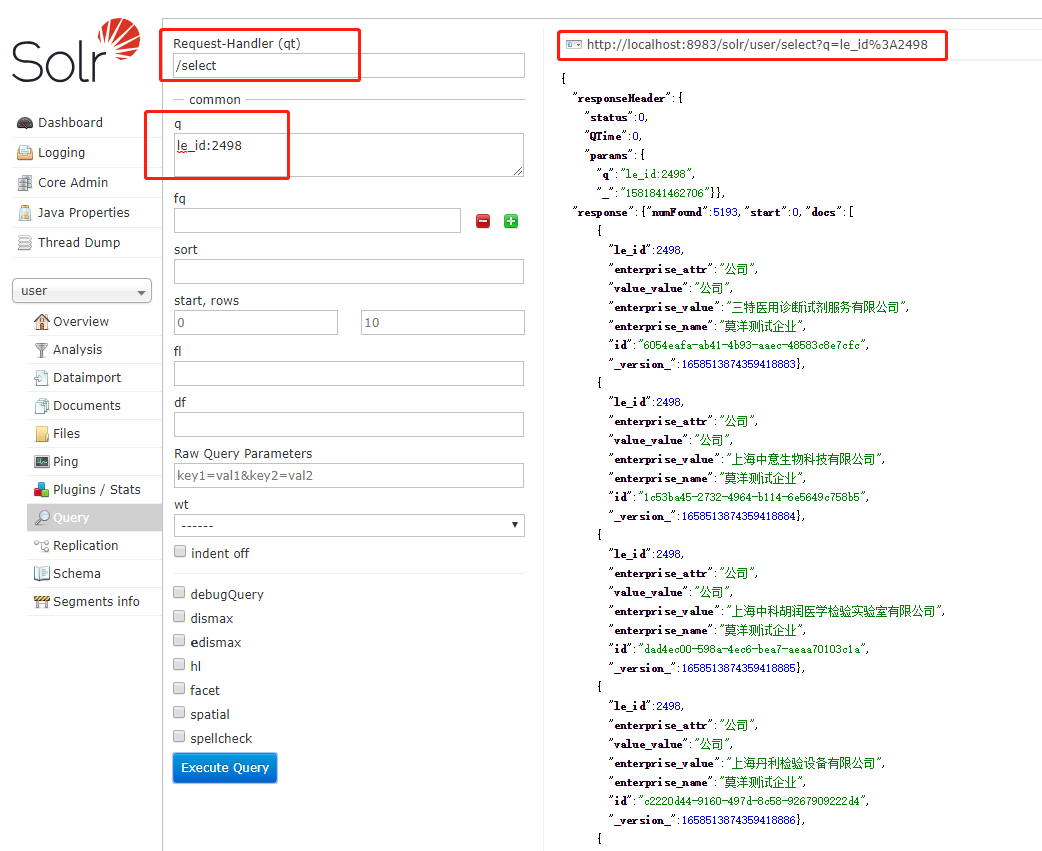
指定标准查询分析器的条件
检索词
有2种类型的检索词:单词和短语
- 单词是一个单独的词,例如 “test” 或 “hello”
- 短语是一组由双引号包围的词组,如 “hello dolly”
多个检索词可以与布尔运算符组合在一起,形成更复杂的查询(如下所述):
操作符
条件修饰
根据需要,Solr支持多样的能够增加灵活度或精度的检索词模糊匹配。这些模糊匹配包括可以进行模糊查询或一般查询的通配符。
- 通配符查询
solr标准查询支持在单词中使用一个或多个通配符。通配符可以应用于单词,但不能用于短语中。
通配符查询类型
字符
示例
单个字符(匹配单个字符)
?
搜索字符串te?t将匹配 test 和 text。
多个字符(匹配0个或多个字符)
*
tes* -> test, testing, 或 tester。
te*t -> test 或 text.
*est -> pest 或 test
模糊查询
在单词词尾添加波浪号 〜 符号1
roam~
这个搜索将匹配像 roams、foam、foams。它也将匹配“roam”这个词本身。
一个可选的距离参数指定的最大可编辑数介于0和2之间,默认为2。例如:1
roam~1
这将匹配 roams 和 foam 等术语,但不包括 foams,因为它的编辑距离为“2”。
邻近搜索
邻近查询将查询一个检索词与另一个检索词有指定距离的结果。
执行邻近查询,在查询检索词组最后添加~符号和一个数值。比如,要查询文档中的 “apache” 和 “jakarta” 之间有10个单词:1
"jakarta apache"~10
这里所说的距离,是匹配指定检索词所需移动单词的数量。在上面的例子中,“apache” 和 “jakarta” 之间有10个词的距离则匹配。如果 “apache” 在 “jakarta” 前面,则需要更大的数,使 “apache” 能够在 “jakarta” 后面。
范围搜索
范围搜索指定字段的值范围。如果是非数字字段,按照字典排序。
比如,下面的例子是匹配所有的mod_date检索字段在20020101和20030101之间的结果(包括20020101和20030101):1
mod_date:[20020101 TO 20030101]
范围查询不限于日期字段或数字格式,还可以查询非日期字段:
1
title:{Aida TO Carmen}
将会查询所有 title 在 Aida 与 Carmen之间的文档(不包括Aida 和 Carmen)。
通过括号决定是否包括上限和下限:
1.方括号[]表示包含上限和下限;
2.花括号{}表示不包含上限和下限;
3.也可以同时使用两种括号,表示一个包含,一个不包含,比如:count:{ 1 TO 10 ]。控制相关度查询
加权查询允许通过加权单词控制文档的相关度。比如,你查询 “jakarta apache” ,并且希望 “jakarta” 相关度更高,你可以使用 ^符号,比如:1
jakarta^4 apache
默认,加权因子是1。尽管加权因子必须是正数,但是可以小于1(比如,0.2)。
使用“^=”打分
常量打分查询使用 <query_clause>^=,对整个变量设置指定分值。当你只关心一个特定的匹配条件,不希望其他因素产生影响,比如检索词频率或逆文献频率。
例如:1
(description:blue OR color:blue)^=1.0 text:shoes
查询指定字段
在solr中对数据创建索引是以字段为基准的,这是在solr的managed-schema文件中定义的。
搜索可以利用字段增加查询精度。比如,你可以指定一个字段来搜索,比如一个title字段。
在managed-schema文件中定义一个字段作为默认字段。如果你在查询的时候没有指定字段,solr只搜索默认字段。另外,你可以在查询过程中指定一个字段或字段组合。
要指定一个字段,只需要在检索词前面加上字段和冒号(:),然后就能够使用这个字段进行查询了。
比如,假设一个索引包括两个字段,title和text,并且text是默认字段。如果你想查询查询名为The Right Way的文档和包含don’t go this way的文档,你可以使用下面的检索方法:1
2title:"The Right Way" AND text:"don't go this way"
title:"Do it right" AND "don't go this way"既然text是默认字段,可以不用明确指明;所以,上面第二种方式忽略它。
默认字段先于指定字段,所以查询title:Do it right将只在title字段查询Do,在默认字段上查询it和right。标准查询支持的布尔运算符
布尔运算符可以在查询时使用布尔逻辑,在匹配文档时查询存在或不存在指定检索词或条件。下面的表格总结了标准查询可以使用的布尔运算符。
布尔运算符
替代符号
描述
AND
&&
要求在布尔运算符两侧的任何一方都要匹配。
NOT
!
要求对应搜索词不存在。
OR
||
要求布尔运算符两侧一个或两个检索词都会出现。
+
要求符号”+”后的项必须在文档相应的域中存在
-
要求符号”-”后的项不存在。
布尔运算符允许使用逻辑运算符的组合检索词。Lucene支持AND、+、OR、NOT和-作为逻辑运算符。
注:
当使用关键词(如AND、NOT)指定布尔表达式时,必须使用大写字母。布尔运算符OR (||)
OR运算符是默认运算符。这就意味着,如果两个检索词之间没有布尔表达式,默认使用OR运算符。OR运算符链接的两个检索词,如果任何一个检索词存在文档中,这个文档将成为匹配文档。这就相当于并集。可以使用||代替OR。查询包含 “jakarta apache” 或 “jakarta,”,可以使用1
2"jakarta apache" jakarta
"jakarta apache" OR jakarta布尔运算符AND (&&)
AND操作要求在一个文档中包含两个检索词,这相当于交集。可以使用&&代替AND。
要查询包含 “jakarta apache” 和 “Apache Lucene”的文档,可以使用1
2"jakarta apache" AND "Apache Lucene"
"jakarta apache" && "Apache Lucene"布尔运算符NOT (!)
NOT运算符不包括那些包含NOT之后的检索词的文档。这相当于差集。可以使用!代替NOT。
要查询包含 “jakarta apache” 但不包括 “Apache Lucene”的文档,可以使用1
2"jakarta apache" NOT "Apache Lucene"
"jakarta apache" ! "Apache Lucene"布尔运算符+
+要求+之后检索词存在于至少一个文档的某个字段中,以便查询返回。
比如,要查询文件,必须包含”jakarta”,可能或可能不包含”lucene”,可以使用查询1
+jakarta lucene
布尔运算符-
-或“禁止”运算符不包括符号后包含检索词的文件。
比如,要查询文件,必须包含”jakarta apache”,不包含”Apache Lucene”,可以使用查询1
"jakarta apache" -"Apache Lucene"
转义特殊字符
在solr的一次查询中,下列字符存在特殊含义:+ - && || ! ( ) { } [ ] ^ “ ~ * ? : /。
为了让solr解读这些字符时使用字面量,而不是特殊字符,可以在字符前加一个反斜杠\字符。例如,查询(1+1):2,为了不让solr把+、括号()对两个检索词进行子查询,需要在特殊字符前加上反斜杠转义字符:\(1\+1\)\:2。分组子查询
支持使用括号来组合子句形式的子查询。如果你想控制一个查询的布尔逻辑,这是非常有用的。
The query below searches for either “jakarta” or “apache” and “website”:
下面的查询搜索 “jakarta” 或 “apache” 和 “website”:(jakarta OR apache) AND website。
这样增加了查询的准确性,“website”必须存在,需要”jakarta” 或 “apache” 存在。group从句作为字段
在查询过程中多一个字段使用两个或多个布尔运算符,需要使用括号组织布尔从句。比如,下面查询title字段必须包含”return”单词和”pink panther”短语:title:(+return +”pink panther”)。注释
在查询串中支持C语言风格的注释。比如:”jakarta apache” /* 这是在一个普通查询串中间的注释 */ OR jakarta。注释可以被嵌套。
DisMax 查询解析器
DisMax查询解析器设计用于处理用户输入的简单短语(无复杂语法),并根据每个字段的重要性使用不同的权重(升序)在多个字段中搜索单个术语。其他选项允许用户根据特定于每个用例的规则(独立于用户输入)影响分数。
一般来说,与“Lucene”Solr查询解析器的接口相比,DisMax查询解析器的接口更像Google的接口。这种相似性使DisMax成为许多用户应用程序的适当查询解析器。它接受一个简单的语法,很少产生错误消息。
DisMax查询解析器主要设计为易于使用,并且几乎可以接受任何输入而不返回错误。
语法:略
扩展的 DisMax 查询解析器:eDismax
除了支持所有的 DisMax 查询解析器参数外,同时支持完整的 Lucene 查询分析器语法,它与 Solr 的标准查询解析器具有相同的增强功能。
Solr的函数查询
函数查询允许你使用一个或多个数字字段的真实值生成一个相关性分数,函数查询在standard,DisMax,eDisMax下都能使用。
查询函数可以是常量,字段或者其他函数的组合。使用函数可以影响结果的排序。
使用Function Query
直接向QParser指定函数参数,如func或frange:
1
q={!func}div(popularity,price)&fq={!frange l=1000}customer_ratings
在排序时使用
1
sort=div(popularity,price) desc, score desc
将函数的结果作为伪字段(pseudo-fields)添加到查询结果中的文档
1
&fl=sum(x, y),id,a,b,c,score
指定函数的一个参数:在dDisMax中指定boost参数,在DisMax中指定bf参数
1
q=dismax&bf="ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3"
在Lucene的QParser中使用val关键字指定函数
1
q=_val_:mynumericfield _val_:"recip(rord(myfield),1,2,3)"
使用Function Query
Solr中的可用函数
todo
响应编写器
Solr 支持各种响应编写器,以确保查询响应可以被适当的语言或应用程序解析。
该 wt 参数选择要使用的响应编写器。
- JSON
- XML
- CSV
- GeoJSON
- javabin
- PHP
- PHPS
- python
- ruby
- smile
- velocity
- XLSX
- XSLT
JSON响应编写器
默认的 Solr 响应编写器是 JsonResponseWriter。在请求中没有设置 wt 参数,则默认情况下将获得 JSON。
参数介绍:略
标准的XML响应编写器
XML 响应编写器是 Solr 当前包含的最通用和可重用的响应编写器。这是大多数关于 Solr 查询响应的讨论和文档中使用的格式。
参数介绍:略
Solr的提交方式
Solr的提交方式有两种,标准提交(硬提交,hard commit)和软提交(soft commit)。
Hard commit
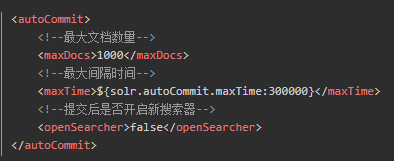
- 默认的提交即硬提交,commit之后会立刻将文档同步到硬盘,在开启新搜索器之前会阻塞,直到同步完成。
- 默认情况下commit后会开启一个新搜索器(newSearcher),然后进行预热,预热完成后顶替旧搜索器,使旧缓存失效,但是开启新searcher及预热的过程(IO消耗)耗费资源过大,且可能被阻塞,所以应尽量避免在高峰期开启newsearcher,搜索器同一时间只能有一个处于active状态。
- 为了避免频繁commit,solr提供了autocommit功能,可以设置每隔多久提交一次,或者待提交文档量达到阀值提交一次,并且可定义是否在提交后开启新的搜索器,若不开启,则缓存不能够被刷新,新更新文档不能够被实时读取到。
Soft commit
- 软提交是将文档提交到内存,并不实时写入硬盘,减少了耗时的I/O操作。
- 为了保证实时搜索,solr在软提交基础上引入了近实时搜索(NRT),NRT并不会被文档更新所阻塞,也不会等待文档合并完成再打开一个搜索器。
- 在lucene4.x 之前,solr采用NRTManager实现NRT,之后使用ControlledRealTimeReopenThread实现,它通过IndexWriter对象来监控内存中的文档变化,从而得到最新的文档信息,该过程既不需要高耗时的I/O操作,也不需要刷新搜索器,所以非常之快,耗费资源很少。
- 所以近实时搜索(NRT)是软提交的一个特性。
- 同样的软提交也支持自动提交的方式,配置如下:
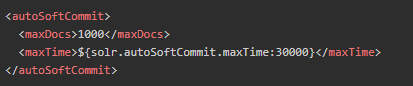
结合优化
上述两种提交方式并不冲突,试想我们程序使用了软提交,但何时可以把数据真正同步到磁盘呢?这时候就可以两者结合达到目的。我们设置每隔5000ms进行一次软提交,文档存入了内存,也可以实时搜索,然后每隔300000ms又会进行进行一次硬提交,同步到磁盘,无需刷新Searcher,如此两者兼顾。在配置文件中配置后,在客户端就不需要维护提交方式和提交时间了。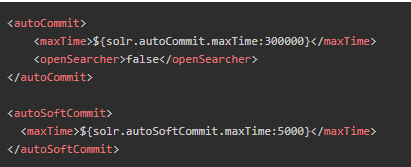
导出Solr结果集
介绍
- 可以使用特殊的秩查询解析器和响应编写器来导出完全排序的结果集,这种解析器和响应编写器专门设计用于处理涉及排序和导出数百万条记录的场景。
- 此功能使用 stream 排序技术,在毫秒内开始发送记录,并继续对结果进行 stream 处理,直到整个结果集被排序并且导出为止。
- 此功能可能有用的情况包括:会话分析、分布式合并联接、时间序列汇总、高基数字段上的聚合、完全分布式字段合并和基于排序的统计信息。
请求结果导出
- 可以使用 /export 来请求导出查询的结果集。
- 所有查询都必须包括 sort 和 fl 参数,否则查询将返回一个错误。过滤器查询也被支持。
- 受支持的响应编写器是 json 和 javabin。由于向后兼容性的原因,wt=xsort也被支持作为输入,但是 wt=xsort 与 wt=json 的行为相同。默认的输出格式是 json。
示例:1
http://localhost:8983/solr/core_name/export?q=my-query&sort=severity+desc,timestamp+desc&fl=severity,timestamp,msg
SolrJ
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图: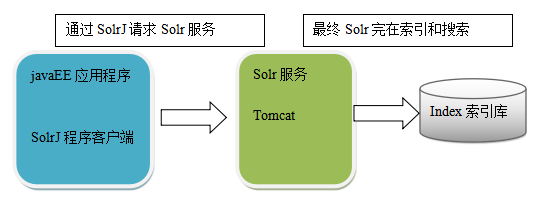
demo代码:详见cfa-tagging项目的SolrJTest.java。
SolrTag类定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51//忽略未匹配到的字段
(ignoreUnknown = true)
public class SolrTag {
// solr查询若直接将数据转为对象,需要指定Field,该值需要和managed-schema配置Field的name一致
("leId")
private Integer leId;
("enterpriseName")
private String enterpriseName;
("enterpriseAttr")
private String enterpriseAttr;
("enterpriseValue")
private String enterpriseValue;
("valueValue")
private String valueValue;
public Integer getLeId() {
return leId;
}
public void setLeId(Integer leId) {
this.leId = leId;
}
public String getEnterpriseName() {
return enterpriseName;
}
public void setEnterpriseName(String enterpriseName) {
this.enterpriseName = enterpriseName;
}
public String getEnterpriseAttr() {
return enterpriseAttr;
}
public void setEnterpriseAttr(String enterpriseAttr) {
this.enterpriseAttr = enterpriseAttr;
}
public String getEnterpriseValue() {
return enterpriseValue;
}
public void setEnterpriseValue(String enterpriseValue) {
this.enterpriseValue = enterpriseValue;
}
public String getValueValue() {
return valueValue;
}
public void setValueValue(String valueValue) {
this.valueValue = valueValue;
}
public String toString() {
return "SolrTag [leId=" + leId + ", enterpriseName=" + enterpriseName + ", enterpriseAttr=" + enterpriseAttr
+ ", enterpriseValue=" + enterpriseValue + ", valueValue=" + valueValue + "]";
}SolrJTest单元测试类定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326/**
* Description : SolrJ CRUD操作的单元测试类
*/
(SpringRunner.class)
@SpringBootTest
@WebAppConfiguration
public class SolrJTest {
SolrTagMapper solrTagMapper;
private SolrClient solrClient;
/**
* 初始化SolrClient
*/
public void setUp() throws Exception {
String solrUrl = "http://localhost:8983/solr/c4c_tag";
solrClient = new HttpSolrClient.Builder(solrUrl).build();
}
/**
* 查询所有字段
*/
public void queryFields() throws Exception {
SchemaRequest.Fields queryFields = new SchemaRequest.Fields();
NamedList<Object> existFields = solrClient.request(queryFields);
Iterator<Entry<String, Object>> iter = existFields.iterator();
while (iter.hasNext()) {
Entry<String, Object> next = iter.next();
System.out.println(next.getKey() + ":" + next.getValue());
}
}
/**
* 添加字段,包括字段的名称、类型、是否存储,是否索引等
*/
public void addFields() throws Exception {
List<Map<String, Object>> fieldAttributesList = new ArrayList<>();
Map<String, Object> fieldAttributes = new HashMap<>();
// 域名
fieldAttributes.put("name", "leId");
// 域的类型,可以是string,pint,如果需要分词设为text_ik
fieldAttributes.put("type", "pint");
// 是否索引,默认为true
fieldAttributes.put("indexed", true);
// 是否存储,默认为true
fieldAttributes.put("stored", true);
// 是否多值,默认为false
fieldAttributes.put("multiValued", false);
// 是否必须,默认false,schema文件中有一个id已默认必须
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "enterpriseName");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "enterpriseAttr");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "enterpriseValue");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "valueValue");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
SchemaRequest.AddField addField = null;
for (Map<String, Object> map : fieldAttributesList) {
addField = new SchemaRequest.AddField(map);
solrClient.request(addField);
}
}
/**
* 添加字段,包括字段的名称、类型、是否存储,是否索引等
*/
public void deleteField() throws Exception {
SchemaRequest.DeleteField delField = new SchemaRequest.DeleteField("delField");
solrClient.request(delField);
}
/**
* 通过对象添加单条数据,若添加时id已存在,那么solr会执行修改操作
*/
public void addBean() throws Exception {
SolrTag tag = new SolrTag();
tag.setLeId(1);
tag.setEnterpriseName("国企");
tag.setEnterpriseAttr("2-5 年");
tag.setEnterpriseValue("AA有限公司");
tag.setValueValue("IT行业");
solrClient.addBean(tag);
solrClient.commit();
}
/**
* 批量添加
*/
public void addBeans() throws Exception {
// 从数据库查出所有的记录
List<SolrTag> solrTags = solrTagMapper.listAll();
// 添加
solrClient.addBeans(solrTags);
solrClient.commit();
}
/**
* 通过document添加单条数据
*/
public void addDocument() throws Exception {
SolrInputDocument document = new SolrInputDocument();
document.addField("leId", 2);
document.addField("enterpriseName", "国企");
document.addField("enterpriseAttr", "3年以上");
document.addField("enterpriseValue", "BB有限公司");
document.addField("valueValue", "IT行业");
solrClient.add(document);
solrClient.commit();
}
/**
* 两种删除方式
*/
public void deleteById() throws Exception {
// 方式一:根据id删除
// solrClient.deleteById(id);
// 方式二:根据查询结构删除
solrClient.deleteByQuery("enterpriseName:国企");
solrClient.commit();
}
/**
* 查询所有/select?q=*:*
*/
public void queryAll() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 限定返回字段/select?q=*:*&fl=param1,param2
*/
public void queryFl() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 设置限定返回字段
solrQuery.setFields("leId", "enterpriseName", "enterpriseAttr");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 分页/select?q=*:*&rows=5&start=0
*/
public void queryPage() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 设置分页信息
solrQuery.setStart(0);
solrQuery.setRows(20);
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 增加限定条件/select?q=*:*&fq=leId:{70 TO *]&fq=valueValue:公司
*/
public void queryFq() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 设置限定条件
solrQuery.setFilterQueries("leId:{70 TO *]", "valueValue:公司");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 使用函数,并设置别名/select?q=*:*&fl:"leId", "alias:sum(leId,0.1)", "valueValue"
*/
public void queryFunction() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 将函数的结果作为伪字段,添加到查询结果中的文档
solrQuery.setFields("leId", "alias:sum(leId,0.1)", "valueValue");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 添加排序/select?q=*:*&sort:leId desc
*/
public void querySort() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 添加排序
solrQuery.setSort("leId", SolrQuery.ORDER.desc);
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 分组/select?q=*:*&group.limit=20&group.offset=0&group.ngroups=true&wt=javabin&version=2&group.field=enterpriseName&group=true
* group=true:设置开启分组查询 group.field=xx:设置分组字段 group.limit=20:设置分组后展示分组下数据量
* group.ngroups=true:设置为true表示会返回分组的分组
*/
public void queryGroup() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 开启分组功能
solrQuery.set(GroupParams.GROUP, true);
// 按照enterpriseName分组
solrQuery.set(GroupParams.GROUP_FIELD, "enterpriseName");
// 设置每个分组里从第几条数据开始返回,用于组内分页,这里不进行分页
solrQuery.set(GroupParams.GROUP_OFFSET, 0);
// 设置每个分组最多返回几条数据
solrQuery.set(GroupParams.GROUP_LIMIT, 20);
// 是否返回总的组数
solrQuery.set(GroupParams.GROUP_TOTAL_COUNT, true);
// //组内排序
// solrQuery.set(GroupParams.GROUP_SORT,"filed asc");
// //组间排序
// solrQuery.set(CommonParams.SORT,"filed desc");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果列表
GroupResponse groupResponse = response.getGroupResponse();
// 获取根据不同分组方式查询到的结果
List<GroupCommand> groupCommandList = groupResponse.getValues();
// 由于这里只有一种分组策略,所以直接取第一个对象
GroupCommand groupCommand = groupCommandList.get(0);
List<Group> groups = groupCommand.getValues();
// 打印每个分组信息
SolrDocumentList list = null;
for (Group group : groups) {
// 获取每个分组内的数据
list = group.getResult();
System.out.println("------------");
for (SolrDocument solrDocument : list) {
// 方便演示,直接转换成json打印
String record = JSON.toJSONString(solrDocument);
System.out.println(record);
}
}
}
}
其它
以下内容属于Solr可选扩展功能:
- 身份验证插件
- hadoop
- 授权插件
- 签名证书SSL
- HDFS存储
- 备份与还原
- ……
以下内容属于集群SolrCloud的功能:
- SolrCloud介绍
- SolrCloud集群部署
- SolrCloud工作原理
- 碎片、副本、索引数据
- 分布式请求
- 扩展与容错
- ZooKeeper搭建
- ZooKeeper控制访问
- ZooKeeper管理配置文件
- SolrCloud的Collections API
- 流表达式
- 并行SQL接口
- 并行SQL体系结构的三个逻辑层组成。
- ……
敏捷-Scrum5大价值观

Scrum价值观是专注、开放、勇气、承诺和尊重。它们非常重要,而且经常被误解,以至于在2016年7月被添加到Scrum指南中。原文如下:
- Respect - Scrum Team members respect each other to be capable, independent people
- Focus - Everyone focuses on the work of the sprint and the goals of the Scrum Team
- Commitment - People personally commit to achieving the goals of the Scrum Team
- Courage - Scrum Team members have courage to do the right thing and work on tough problems
- Openness - The Scrum Team and its stakeholders agree to be open about all the work and the challenges with performing the work
这五个价值观很容易记住,但是很难理解它们的含义,如何应用它们,以及如何在团队和个人中识别它们。没有Scrum的价值观,我们只是在做活动,不会最大化Scrum的好处,使业务敏捷。
Scrum Values: Focus (Part 1 of 5)
Focus(专注):专注于让客户满意。专注于冲刺(sprint)及其目标。
为了更好的完成任务,当我们处理复杂性和不可预测性任务时,专注是必不可少的。
专注有助于经验主义和团队协作。
- 当Scrum团队在一件或两件事情上进行协作时,他们通常会更有效,而不是独立地处理单独的产品待办事项。他们先做一件事,然后再做下一件事。这可以减少来自在制品和冲刺结束时未完成的工作的潜在浪费。虽然Scrum并没有告诉你如何交付,但是focus可以引导团队发现他们最好的工作方式,从而更快地完成工作并将浪费降到最低。
- 当有多个问题时,focus可以帮助团队确定首先要解决的问题,经常检查他们的进度,并在他们努力寻找解决方案时尝试新的实验。
- 当有相互竞争的优先事项时,专注可以帮助团队决定现在最重要的事情是什么。
- 当未来不确定的时候,有一种趋势是渐近明细。专注有助于团队接受不确定性,看看他们今天所知道的,然后迈出一小步。这种方法之所以有效,是因为我们从实践中学习,并且可以根据所学改变方向。
- 开发团队在交付“已完成”增量方面的共同责任,使人们关注整体结果,而不仅仅是每个人可以完成什么。
- 有了产品愿景,就可以专注于我们要去的地方,并且可以帮助团队的判断和决策。
Scrum框架包含有助于提Focus高度的元素。
- 我们的重点是至少在每次冲刺结束时都有一个“完成”的增量。
- Scrum事件和工件有助于创建关注于检查进度和新信息的焦点,因此我们可以以足够频繁的间隔进行调整。
- 我们专注于一个Sprint目标来指导团队交付什么。
- 每个角色都有一个独特的责任感,可以帮助个人知道应该把什么作为他们的优先事项。这最终有助于团队的成果。
- 产品Backlog是一个有序的列表,它创建了对下一步最重要事情的关注。
- 有时间限制的活动会产生一种紧迫感,帮助我们专注于活动的目的。
团队需要不断地和协作地精炼“专注”对他们意味着什么,以便真正最大化Scrum。
Scrum Values: Openness (Part 2 of 5)
Openness(开放):Scrum强调保持开放。
当我们处理复杂性和不可预测性时,开放是必不可少的。
开放性促进了经验主义和协作团队精神。
- 公开我们的工作有助于为我们的进展创造透明度。没有透明度,任何检查和调整的尝试都将是有缺陷的。
- 开放性使团队成员能够寻求帮助。
- 开放性允许团队成员互相提供帮助。
- 开放性使团队成员能够分享他们的观点,感受到同行的意见,并能够支持团队决策。
- 当我们的假设被证明无效时,开放性帮助我们承认错误并改变方向。这适用于我们认为有价值的功能。这也适用于我们选择如何在产品中实现功能。
Scrum框架包含有助于促进开放性的元素。
- 将Sprint时间限制在30天或30天以下,可以促进基于新信息的改变方向的开放性。
- Sprint目标是固定的并提供了指导,但是实现Sprint目标的计划是开放的,可以根据开发团队正在学习的内容进行更改。
- 透明的产品待办事项清单向我们的利益相关者展示了对产品计划(以及未计划的)和下一步可能发生的事情的开放性。
- Sprint回顾的重点是不断改进我们团队的交互、流程和工具,这就要求我们对反馈、反思和改变工作方式持开放态度。
- Sprint评审展示了与利益相关者分享进展的开放性,以及对反馈和与他们合作的开放性。
团队需要不断地和协作地精炼“开放”对他们意味着什么,以便真正最大化Scrum。
# Scrum Values: Courage (Part 3 of 5)
Courage(勇气):Scrum团队成员有勇气做正确的事情并解决棘手的问题。
勇气是解决复杂问题和培养高绩效团队的关键。
勇气有助于经验主义和团队合作。
- 在压力下保持进展的透明度,以便更快地交付成果,这需要勇气。
- 不让我们的利益相关者放弃工作需要勇气。
- 寻求帮助或承认我们不知道怎么做需要勇气。
- 当其他人没有履行对团队的承诺时,让他们承担责任需要勇气。
- 我们可能会发现我们制造了顾客不想要的东西。承认我们的假设是错误的并改变方向需要勇气。
- 尝试建立我们从未建立过的东西需要勇气,不知道它是否会起作用。
- 与团队成员分享不同意见并进行富有成效的冲突需要勇气。
- 承认错误需要勇气。这可能适用于我们的技术工作、我们的决定,或者我们的行为方式。
Scrum框架包含有助于提升勇气的元素。
- 每一次Scrum活动都是一个检验和适应的机会。这种内在的假设,即改变方向是可以的,这使我们有了勇气。我们可以改变建设方向。我们可以改变建设方向。
- 冲刺的时间限制了失败对冲刺长度的影响。这给了我们勇气去尝试新事物,去实验,去学习。
- Scrum的三个角色和他们各自的职责提升了勇气。产品负责人对产品价值最大化负责,因此她可以通过对低价值特征说“不”来表现勇气。开发团队负责交付高质量的产品,在压力下降低质量时,他们可以通过说“不”来展示勇气。
- 通过Sprint Backlog和产品Backlog,我们对计划的工作是透明的。通过向利益相关者展示完成的增量,我们对进度是透明的。透明需要勇气,透明有助于我们建立信任。信任越多,勇气越大。这是一个良性循环。
- Sprint回顾的目的是检查我们作为Scrum团队的情况,并确定改进的行动。这使我们有勇气提出我们如何合作的问题。这使我们有勇气去尝试新事物,去想要更多。
这仅仅是几个例子,说明Scrum“勇气”如何在Scrum Team中体现,帮助他们最大限度地发挥Scrum的好处。还有很多。团队需要不断地和协作地精炼“勇气”对他们意味着什么,以便真正最大化Scrum。
Scrum Values: Commitment (Part 4 of 5)
Commitment(承诺):对致力于实现Scrum团队目标做出承诺。
承诺对于解决复杂问题和发展高绩效团队至关重要。Scrum中的承诺常常被误解为在指定日期交付一个指定范围的承诺。这从来不是Scrum指南中承诺这个词的本意。我希望这篇文章有助于阐明承诺的价值。
承诺有助于经验主义和团队协作。
- 当我们致力于团队的成功,而不仅仅是关心我们个人的成就时,这就创造了一个信任、高效解决问题和高团队标准的环境。
- 当我们致力于全面地进行Scrum时,而不仅仅是挑选容易的部分,我们可以充分体验透明、检查和适应的好处。
- 致力于持续改进,更容易根据新信息或经验数据改变方向。
- 承诺就是全力以赴。我们不能预测或控制产品开发中的所有复杂性,但我们可以承诺采取行动和调整我们的行为,基于反馈和新的学习。
- 当我们致力于交付价值时,我们会感觉到一种更强烈的共同目标感,这种意识驱使我们去合作。
Scrum框架包括有助于促进承诺的元素。
- 每个Scrum角色都有明确的责任,这是一种承诺。
1.产品经理(Product Owner)通过做出最佳决策来优化产品的价值,而不是简单地试图取悦每一个利益相关者,以此来证明自己的承诺。
2.开发团队通过创建一个符合他们“完成”定义的增量来展示他们的承诺,而不是几乎完成的事情。
3.Scrum Master通过维护Scrum框架来展示承诺,这意味着我们不会在压力下扩展Sprint或其他时间框来完成任务。Scrum Master通过消除Scrum团队无法解决的障碍来展示承诺,而不是容忍组织的现状。 - 在Sprint结束时交付一个“完成”增量可以促进对质量和持续改进的承诺。
- 产品待办事项清单能够保证透明度。涉众可以看到产品和当前工单中当前计划的内容。
- Sprint Backlog使我们能够致力于提高进度的透明度。开发团队拥有Sprint Backlog,它总是根据我们所学到的来反映我们当前的进度。
- Scrum每日站会是开发团队展示对彼此承诺的机会。他们合作检查他们的进展并调整他们的计划。它们决定了如何才能最好地协同工作来实现Sprint目标。
- Sprint回顾会促进团队对持续改进的承诺。我们检查我们的流程、工具和交互,确定并致力于可操作的改进。
这只是几个例子,说明Scrum的“承诺”如何在Scrum Team内部实现,以帮助他们最大化Scrum的好处。还有很多。团队需要不断地和协作地精炼“承诺”对他们意味着什么,以便真正最大化Scrum。
Scrum Values: Respect (Part 5 of 5)
Respect(尊重):Scrum团队成员相互尊重,认为自己是有能力、独立的人。
尊重对于解决复杂问题和发展高绩效团队至关重要。这似乎是显而易见的,所以我将与大家分享Scrum中尊重价值的一些更微妙的例子。
尊重有助于经验主义和团队合作。
- 如果我们尊重人们天生的足智多谋、富有创造力和能够合作解决复杂问题的能力,那么我们就赋予了自组织团队权力并使之成为可能。
- 通过尊重人们不同的背景、经验和技能范围,团队能够以创造性的方式有效地解决复杂的问题。
- 当我们尊重人们是由自主、掌握和目标所激励的时候,我们就创造了一个能吸引人们的环境,使团队变得比他们的部分总和还要强大。
- 如果我们尊重人们在考虑到他们当时所知道的情况和他们目前的资源的情况下正在尽最大努力,我们就能实现透明度。我们可以根据所学改变方向。
- 当我们表现出对他人的尊重,并假定他们有良好的意愿时,我们可以进行艰难的对话,帮助我们找出解决冲突的方法,并作为一个团队变得更强大。
- 当尊重所有的意见和观点时,我们可以确保每个人都有机会被倾听。当我们感觉自己被听到时,即使这个决定不是我们的偏好,也有可能完全支持团队的决定。
Scrum框架包括有助于促进尊重的元素。
- 整个Scrum团队参加Sprint计划、Sprint回顾和Sprint回顾。这促进了对每个角色、责任和不同观点的尊重。
- 开发团队是跨职能的,这意味着作为一个整体,它拥有交付“完成”产品增量所需的所有技能。这促进了对每个人的经验、技能和想法的尊重。这也促进了学习和成长。
- Sprint Backlog归开发团队所有。因为他们是做这项工作的人,所以他们决定在一次冲刺中能做多少以及如何做这项工作。这表明了对他们的知识和技能的尊重,以及对以可持续的速度工作的尊重。
- 通过在Sprint审查中只审查“完成”的产品,我们为真正的进展带来了透明度。这表明了对我们利益相关者的尊重。
- 产品所有者寻求利益相关者的意见,与之合作,并为其设定现实的期望。这是对利益相关者的又一次尊重。
- Scrum Master关注的是Scrum团队的健康和Scrum的有效使用。拥有一个专注于教学、促进和指导的角色,表明了对人和团队及其成长能力的尊重。
- Scrum专注于交付价值,这表明了我们对组织的尊重,因为它不会把钱花在低价值的特性或可能永远不会使用的东西上。
- 在Sprint结束时有一个潜在的可释放的增量,这表明了我们对组织的尊重,因为我们没有强迫更多的投资来实现价值。它给组织提供投资决策的灵活性。
这仅仅是几个例子,说明Scrum的价值如何在Scrum Team内部体现,以帮助他们最大化Scrum的好处。还有很多。团队需要不断地和协作地精炼“尊重”对他们意味着什么,以便真正最大化Scrum。
总结
当Scrum团队体现并践行承诺、勇气、专注、开放和尊重的价值观时,Scrum的透明、检查和适应的支柱就会活跃起来,并为每个人建立信任。Scrum团队成员在处理Scrum事件、角色和工件时学习和探索这些价值观。文章参考自A Wet Weekend with the Scrum Values
敏捷-Scrum三大支柱
序言
这三个支柱是在实现Scrum时驱动其他流程的动力,并解释了其中许多流程、仪式和行为背后的原因。理解这三个支柱可以在您的项目中更好地实现Scrum,也许还可以解释为什么事情是以这样的方式完成的。
Scrum 理论的三大支柱
Scrum 基于经验过程控制理论,或称之为经验主义。经验主义主张知识源自实际经验以及 当前已知情况下做出的决定所获得。Scrum 采纳一种迭代、增量式的方法来优化对未来的 预测和控制风险。
透明、检视和适应是经验过程控制的三大支柱,支撑起每一个经验过程的实施。
透明
过程中的关键环节对于那些对产出负责的人必须是显而易见的。要拥有透明,就要为这些 关键环节制定统一的标准,这样所有留意这些环节的人都会对观察到的事物有统一的理 解。
例如
- 所有参与者谈及过程时都必须使用统一的术语。
- 负责完成工作和检视结果增量的人必须对“完成”的定义,有一致的理解。
检视
Scrum 的使用者必须经常检视 Scrum 的工件和完成 Sprint 目标的进展,以便发现不必要 的差异。检视不应该过于频繁而阻碍工作本身。当检视是由技能娴熟的检视者在工作中勤 勉地执行时,效果最佳。
适应
如果检视者发现过程中的一个或多个方面偏离可接受范围以外,并且将会导致产品不可接 受时,就必须对过程或过程化的内容加以调整。调整工作必须尽快执行如此才能最小化进 一步的偏离。
三大支柱的作用
Scrum之所以能够工作,并不是因为它有三个角色、五个事件和三个工件,而是因为它坚持迭代的、基于价值的增量交付的基本敏捷原则,通过频繁地收集客户反馈和接受变更。而Scrum的三大支柱为收集需求,发现问题,解决问题,改进问题提供支撑。这导致更快的上市时间、更好的交付可预测性、更高的客户响应能力、通过管理不断变化的优先级改变方向的能力、增强的软件质量和改进的风险管理。
与用Scrum相关的推荐资源
重构改善即有代码设计
前言
公司最近在改造一个之前做好的产品级大项目。这个项目之前是用的Spring MVC + jsp做的。现在我们要把这个项目改成 Spring boot + Spring MVC + mybatis + react的架构。改造后的项目将按照业务分成十几个微服务,使用Spring cloud进行服务治理。说是改造但为了满足进度和工期,我们后台的做法是找到对应的模块代码迁移到新的微服务中。在这个过程中我们发现了很架构,性能,编码规范等一系列问题,于是我们这支追求卓越的开发团队一致要求加强过程中对代码的重构。
下面我将给出一些重构切入点以便团队参考。
重构前提
重构也是有前提的。重构就是对既有代码的修改,那么即有代码肯定有他原来的业务逻辑,我们进行重构时一定要满足原来的业务逻辑。那么,我们怎么保证这一点呢?那就是为即将修改的代码建立一组可靠的测试环境。这些测试是必要的,因为尽管遵循重构手法可以使我避免绝大多数引入bug的情形,但我毕竟不是神,还是有可能犯错。所以我需要可靠的测试环境。
在此推荐大家阅读并参照《重构改善即有代码的设计》,《阿里巴巴Java开发手册》等书目进行重构。
重构切入点
移除不必要的属性设值方法
如果你为某个字段提供了设置函数,这就暗示这个字段值可以被改变。如果你不希望在对象被创建之后此字段还有机会被改变,那就不要为它提供设值函数,同时将该字段设置为final。这样你的意图会更加清晰,并且可以排除其值被修改的可能性—-这种可能性往往是非常大的。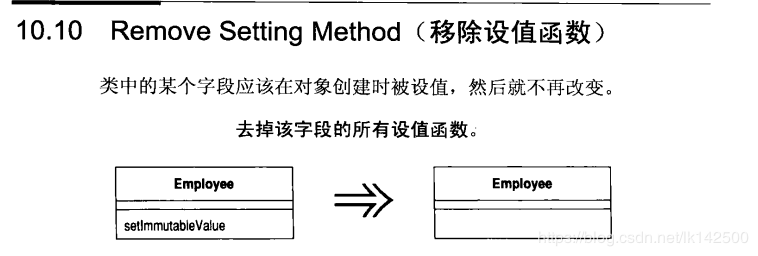
属性下放
超类中的某个字段只被部分(而非全部)子类用到。将这个字段移到需要它的那些子类去。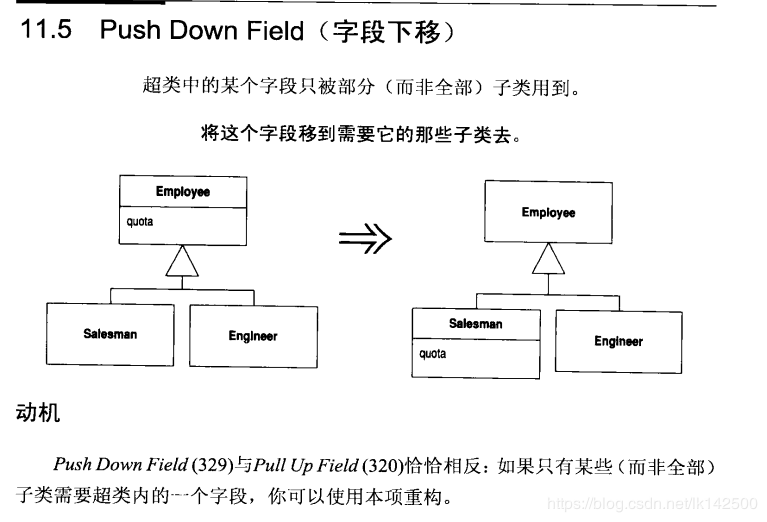
封装字段(Encapsulate Field)
你的类中存在一个public字段,将它声明为private,并提供相应的访问函数。
面向对象的首要原则之一就是封装,或者称为“数据封装”。按此原则你绝对不应该将数据声明为private,否则其他对象就有可能访问甚至修改修改这项数据,而拥有该数据的对象却毫无感觉。
通过这项重构手法,你可以将数据隐藏起来,并提供相应的访问函数。但它毕竟只是第一步。如果一个类除了访问函数不能提供其他行为,它终究只是一个哑巴类。这样的类不能享受对象技术带来的好处。而你知道,浪费任何一个对象都是很不好的。实施Encapsulate Field之后,我会尝试寻找到新建访问函数的代码,看看是否可以通过简单的Move Method轻快的将它们移动到新对象中。
分解并重组过长的方法
要知道,代码块越小,代码的功能就越容易管理,代码的处理和移动也就越轻松,可读性也会更强。对方法的行数进行限制也是很多编码规范中的要求。
分解并重组过长的方法三部曲:抽取方法、移动方法、使用多态。
目的是:对象方法责任合理分配、代码易于维护。
重命名方法名
函数的名称未能揭示函数的用途,则考虑对重命名方法名。
移除未使用的参数
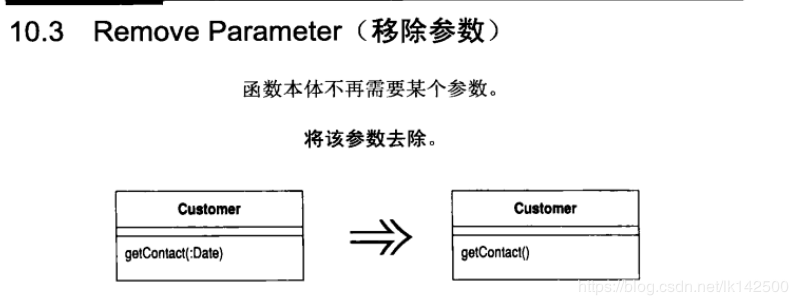
程序员可能经常添加参数,却往往不愿意去掉它们。他们打的如意算盘是:无论如何,多余的参数不会引起任何问题,而且以后还可能用上它。
这是恶魔的诱惑,一定要把它从脑子里赶出去!参数代表着函数所需的信息,不同的参数代表不同的意义。函数调用者必须为每一个参数操心该传什么东西进去。如果你不去掉多余参数,就是让你的每一位用户多操一份心。是很不划算的。
方法下放
超类中的某个方法只被部分(而非全部)子类用到。将这个方法移到需要它的那些子类去。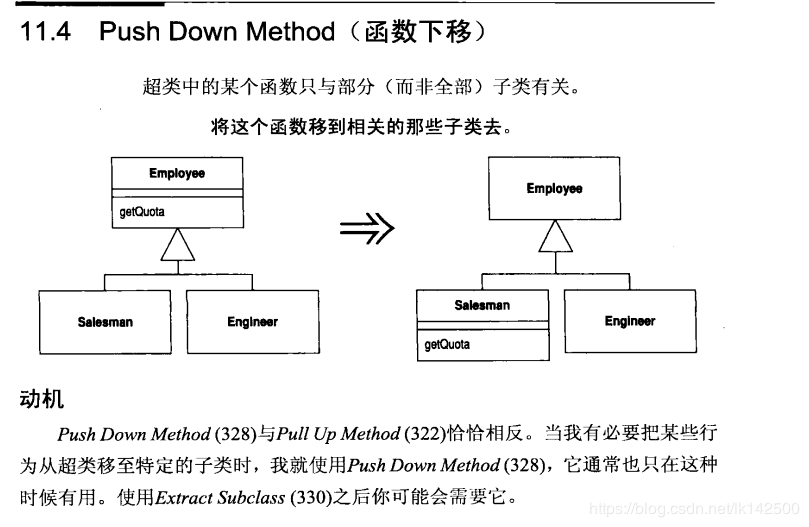
方法隐藏
有一个函数,从来没有被其他任何类使用到,将这个函数设置为private。
重构往往促使你修改函数的可见度。
简化条件语句
简化条件语句(if else、switch case等),使得程序逻辑更加清楚,同时方便扩展。
做法
合并条件语句:能合则合
将多个条件合并,并以一个函数(Extract Method)的形式表示这个条件,即将复 杂逻辑判断的结果赋值给一个有意义的布尔变量名,以提高可读性。
例:1
2
3
4
5
6
7// 伪代码如下
if ((file.open(fileName, "w") != null) && (...) || (...)) { ...
}
// 上面代码应该进行如下重构
final boolean existed = (file.open(fileName, "w") != null) && (...) || (...); if (existed) {
... }合并重复的条件执行片段
重复的条件执行片段,可以提出到条件之外,根据情况提到条件之前或条件之后。- 用守卫语句代替嵌套条件:特别条件直接return
含义:守卫语句就是要么return要么抛异常的语句。
用法:守卫语句通常用在一些不。寻常的条件处,表示一旦发生直接返回。守卫语句可以减少很多if - then - else的跳转,使逻辑变得清晰明了。有的时候,为了使用守卫语句,需要将已有的条件逆转,在逆转条件的时候不要使用非操作,这样不直接,非操作的条件都可以改成反向的条件。 - 引入Null对象:Null对象也是对象,利用多态
注意:空对象一定是常量,它们的任何成分从来不发生变化。因此,我们实现空对象的时候使用单例模式。
做法:主要是考虑 NullObject和isNull方法。
提炼超类
重复代码是系统中最糟糕的东西之一。如果你在不同地方做同一件事,一旦需要修改那些代码,你就得平白做更多的修改。
重复代码的某种形式就是:
两个类以相同的方式做类似的事情,或者以不同的方式做类似的事情。对象提供了一种简化这种情况的机制,那就是继承。
另一种选择就是Extract Class,这两种方案之间的选择就是继承和委托之间的选择。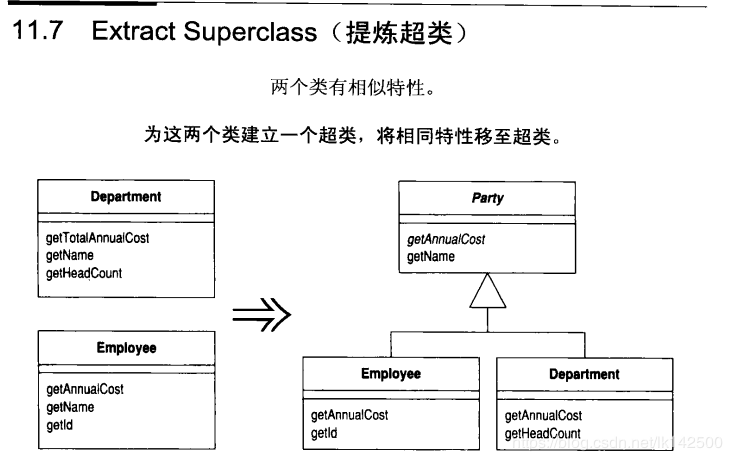
总结
万能切入点,看着不顺眼的地方。但记得前提是你有良好的编码习惯,可靠的测试环境和高覆盖率的自测。
重构的节奏:测试、小修改、测试、小修改、测试、小修改……正是这种节奏让重构得以快速而安全地前进。
User Stories/用户故事
User Stories/用户故事
下文翻译自Mike Cohn的博客

用户故事是敏捷方法的一部分,该方法有助于将重点从编写需求转移到讨论需求。所有的敏捷用户故事都包括一个或两个书面句子,以及关于这个需求的一系列描述。
什么是用户故事?
用户故事是从需要新功能的人员(通常是系统的用户或客户)的角度出发,对功能的简短描述。它们通常遵循一个简单的模板:1
2作为一个<用户类型>,我想要<一些目标>,以便<一些原因>。
As a < type of user >, I want < some goal > so that < some reason >.
用户故事通常写在索引卡或便签上,并排贴在墙壁或桌子上,以方便计划和讨论。因此,他们将人们的注意力从写作需求转移到讨论功需求上。实际上,这些讨论比任何书面内容都重要。
可以展示一些用户故事的示例吗?
用户故事的好处之一是可以描述各种大小的需求。我们可以编写一个用户用户来涵盖大量功能,这些大型用户故事通常被称为史诗(Epics)。这是一个桌面备份产品的史诗级用户故事(epic agile user story)的示例:
- 作为用户,我可以备份整个硬盘。
- As a user, I can backup my entire hard drive.
由于史诗(epic)太大,以至于敏捷团队通常无法在一个迭代中完成,因此在进入开发之前,史诗被拆分为多个较小的用户故事。上面的史诗可以分为数十个(或可能数百个),包括以下两个:
- 作为高级用户,我可以根据文件大小,创建日期和修改日期指定要备份的文件或文件夹。
- 作为用户,我可以指示不备份的文件夹,这样我的备份驱动器就不会充满不需要保存的内容。
如何将细节添加到用户故事?
可以通过两种方式将详细信息添加到用户故事:
- 通过将用户故事分成多个较小的用户故事。
- 通过添加“满足条件”(conditions of satisfaction)。
当一个相对较大的故事分为多个较小的用户故事时,自然会添加详细信息。毕竟,已经写了更多的东西。
满足的条件只是一个高层次的验收测试,在敏捷用户故事完成之后,这个测试才是真实的。考虑以下作为另一个敏捷用户故事示例:
作为市场营销副总裁,我想选择一个假期用来回顾过去广告活动的效果,以便确定有收益的活动。
通过添加以下满足条件,可以将详细信息添加到该用户故事:
- 确保它适用于主要的零售假期:圣诞节,复活节,总统日,母亲节,父亲节,劳动节,元旦。
- 支持跨两个日历年的假期(无跨三个假期)。
- 假期可以从一个假期设置到下一个假期(例如,感恩节至圣诞节)。
- 假期可以设置为假期前的几天。
谁撰写用户故事?

任何人都可以编写用户故事。确保用户故事存在于产品待办列表(product backlog)是PO的责任,但这并不意味着PO是编写它们的人。在一个好的敏捷项目过程中,您应该期望每个团队成员都编写一些用户故事。
另外,请注意,撰写用户故事的人远不如参与讨论的人重要。
用户故事何时编写?
用户故事是在整个敏捷项目中编写的。通常,在敏捷项目开始时会举行一个故事写作研讨会。团队中的每个人都以创建产品待办列表(product backlog)为目标,该待办列表完整描述了在项目过程中或项目三到六个月的发布周期内要被添加的功能。
这些用户故事中肯定会出现一些史诗(Epic)级的需求。随后,史诗将被分解成较小的故事,这些故事更容易放入单个迭代中。此外,任何人都可以随时编写新故事并将其添加到产品待办列表中。
用户故事可以代替需求文档吗?
敏捷项目,特别是Scrum项目,使用产品待办列表(product backlog),这是一个包含了要在产品或服务中开发的功能的有序列表。尽管产品待办列表项(product backlog items)可以满足团队的任何需求,但用户故事已成为产品待办列表项的最佳和最受欢迎的形式。
尽管可以将产品待办列表视为传统项目需求文档的替代品,但重要的是要记住,在讨论故事之前,敏捷用户故事的书面部分(“作为用户,我想要…”)是不完整的。
通常最好将书面部分视为实际需求的参考。用户故事可能指向描述工作流程的图表,显示如何执行计算的电子表格,或PO/团队期望的任何其他工件。
与用户故事相关的推荐资源
Scrummaster保护团队是把双刃剑。
一、【翻译】Scrummaster保护团队是把双刃剑。
下文翻译自Mike Cohn的博客
ScrumMaster的职责之一是保护团队,这是公认的Scrum格言。通常的例子是ScrumMaster必须保护团队不受过于激进的产品经理的影响。这个例子没有什么错,许多团队确实需要得到保护,不受产品经理的影响,因为他们对更多功能的渴望会促使团队在质量方面走捷径。
然而,一个好的ScrumMaster也可以保护团队不受一个更有害的问题的影响:自满。在Scrum实现了一些简单的、早期的改进之后,一些团队变得自满了。他们不再寻求进一步的改进。这取决于团队的ScrumMaster能否保护他们不受这种自满情绪的影响。
因此,一个好的ScrumMaster有时不得不站出来面对一个咄咄逼人的产品经理,并说:“现在不是让这个团队更加努力的时候。他们正在尽可能地努力工作,如果再施加压力,他们很可能会变得马虎。我给一个好的ScrumMaster的建议是:要能掌握团队状态,并知道是时候该干什么了,比如团队该休整了,团队已经准备好了,团队能够做什么,团队是时候可以寻求突破了等。ScrumMaster应该保护团队不受产品经理的影响并且不自满。
直言不讳,表达你的观点?
有些地方可能翻译的不好,你可以留言纠正或是表达你的恶观点。