初识Solr
这几天新接触了一个Apache开源的搜索服务器Solr。
介绍
Solr是一个独立的企业级搜索应用服务器,它对外提供 API 接口。用户可以通过HTTP请求向Solr服务器提出插入数据和查找请求。交互数据主要是 JSON,但也可以是 XML、CSV 或其他格式。
Solr的部署分两种:单节点/SolrCloud集群。
Solr和一般的NoSQL 数据库一样,它是一种非关系数据存储和处理技术。存储结构是文档,文档都是扁平结构的,文档之间不存在相互依赖关系。
为什么要solr:
- solr是将整个索引操作功能封装好了的搜索引擎系统(企业级搜索引擎产品)。
- solr可以部署到单独的服务器上(WEB服务),它可以提供服务,我们的业务系统就只要发送请求,接收响应即 可,降低了业务系统的负载。
- solr部署在专门的服务器上,它的索引库就不会受业务系统服务器存储空间的限制。
- solr支持分布式集群,索引服务的容量和能力可以线性扩展。
windows下安装Solr
安装 1.8+ 版本jdk。
下载solr-8.4.1.zip,并解压到自定义路径下。http://apache.cs.utah.edu/lucene/solr/8.4.1/solr-8.4.1.zip
使用bin\solr.cmd,启动和停止 Solr、创建核心和集合、检查系统的状态…
这里只介绍启动单个Solr节点。
solr 启动、停止、重启命令
solr.cmd start -p 端口号
solr.cmd stop -all
solr.cmd restart -p 端口号
启动 Solr。默认端口:8983。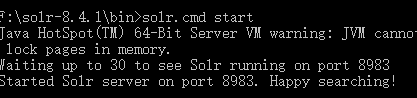
检查Solr是否正在运行。
访问管理控制台:http://localhost:8983/solr/
需要创建一个core才能进行索引和搜索。
接下来就可以把文档存放到这个core上了。
core我的理解是:一个Solr 服务器实例,在实例上可以进行数据的CRUD了。这个数据一般存放类型相同的一类文档。我这边干脆就取名为user,准备放user一类的文档数据了。
一个Solr服务可以有多个core。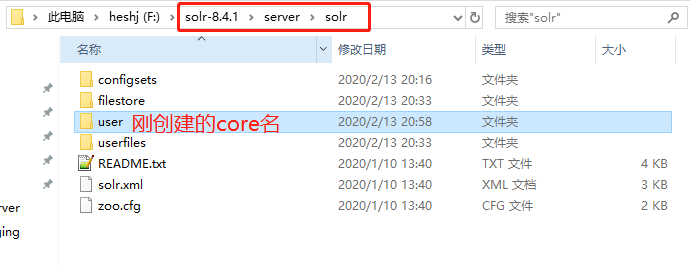
core配置文件介绍: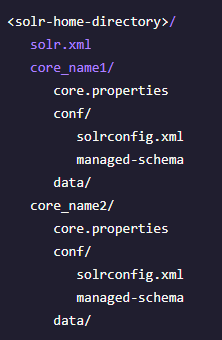
- solr.xml:为Solr 服务器实例指定配置选项。
- 每个 Solr 核心:
- core.properties:为每个核心定义特定的属性,例如其名称、模式的位置以及其他参数。
- solrconfig.xml:控制高级行为。主要定义了Solr的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置。
- managed-schema:描述将要求 Solr 索引的文档。为文档量身配置各种规则。这个配置文件非常重要。可以定义字段如何索引,字段类型有多少filter chain分词器、过滤器…以及其他很重要的配置。修改配置可以通过http请求api修改。
- data/:索引、日志文件等。
字段、字段类型等配置说明
字段定义

name:该字段的名称。
type:该fieldType字段的名称,必填。
indexed:如果为 true,则可以在查询中使用该字段的值来检索匹配的文档。默认true。
…
字段类型定义

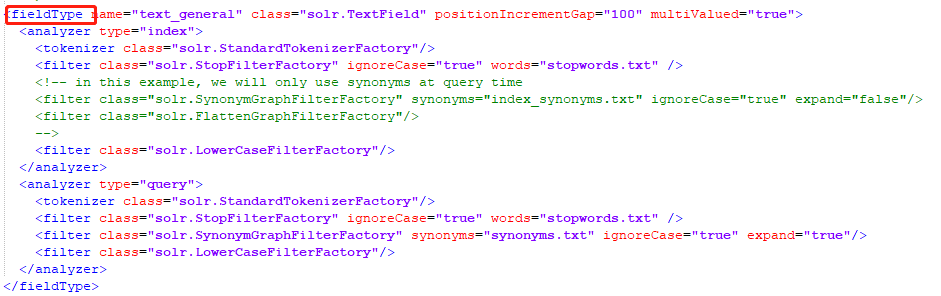
name:fieldType 的名称
class:用于存储和索引此类型数据的类名
索引(indexed):如果为 true,则可以在查询中使用该字段的值来检索匹配的文档。默认true
存储(stored): 如果为 true,则字段的实际值可以通过查询来检索。默认true
docValues:如果为 true,则该字段的值将被放入一个面向列的 DocValues 结构中。
…
Schema API 操作managed-schema
使用 HTTP API 来管理这些配置
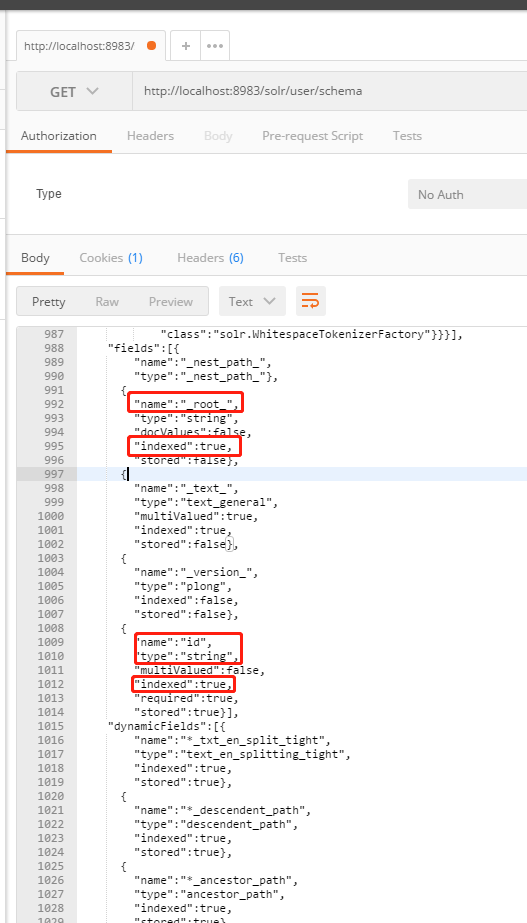
可以看到uesr这个core中,申明的字段和索引情况。
add-field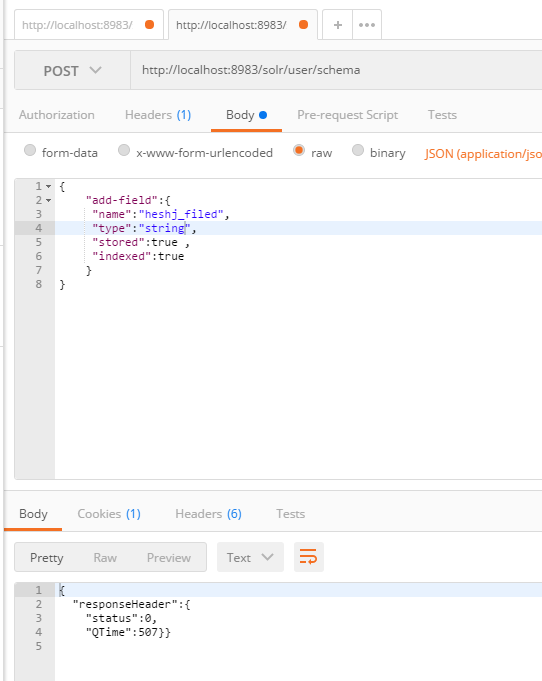
刚定义的字段,在文档中生成了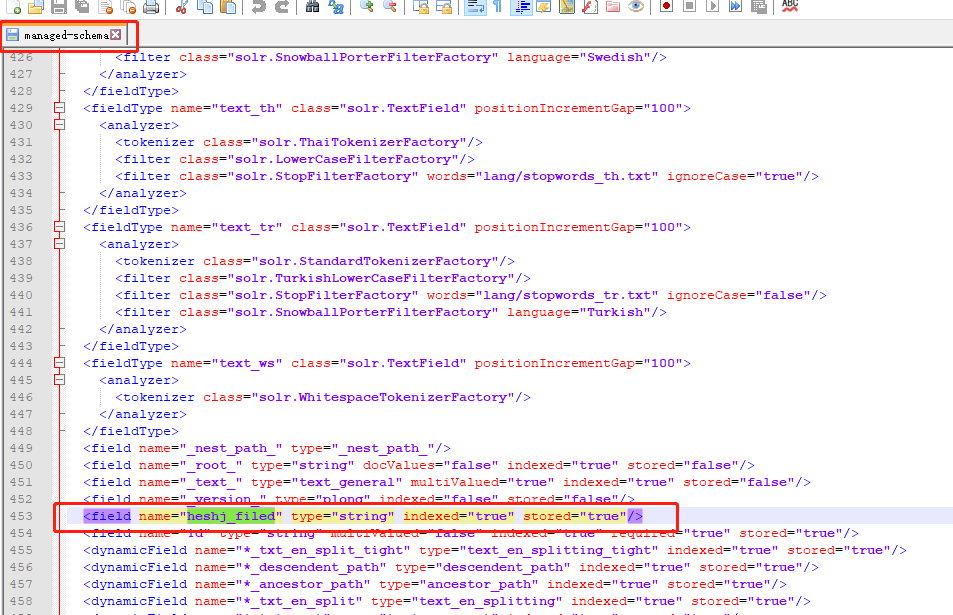
Solr分析器、标记器和过滤器

标记器:Tokenizer 的工作是将文本流分解为令牌,其中每个令牌(通常)是文本中字符的子序列。分析器知道它配置的字段,但 tokenizer 不是。Tokenizers 从字符流(Reader)中读取并生成一系列令牌对象(TokenStream)。
过滤器:过滤器的工作通常比 tokenizer 更容易,因为在大多数情况下,过滤器会依次查看流中的每个标记,并决定是否将其传递、替换或丢弃。
去管理页面,感受下分析器、标记器和过滤器是如何链式运作的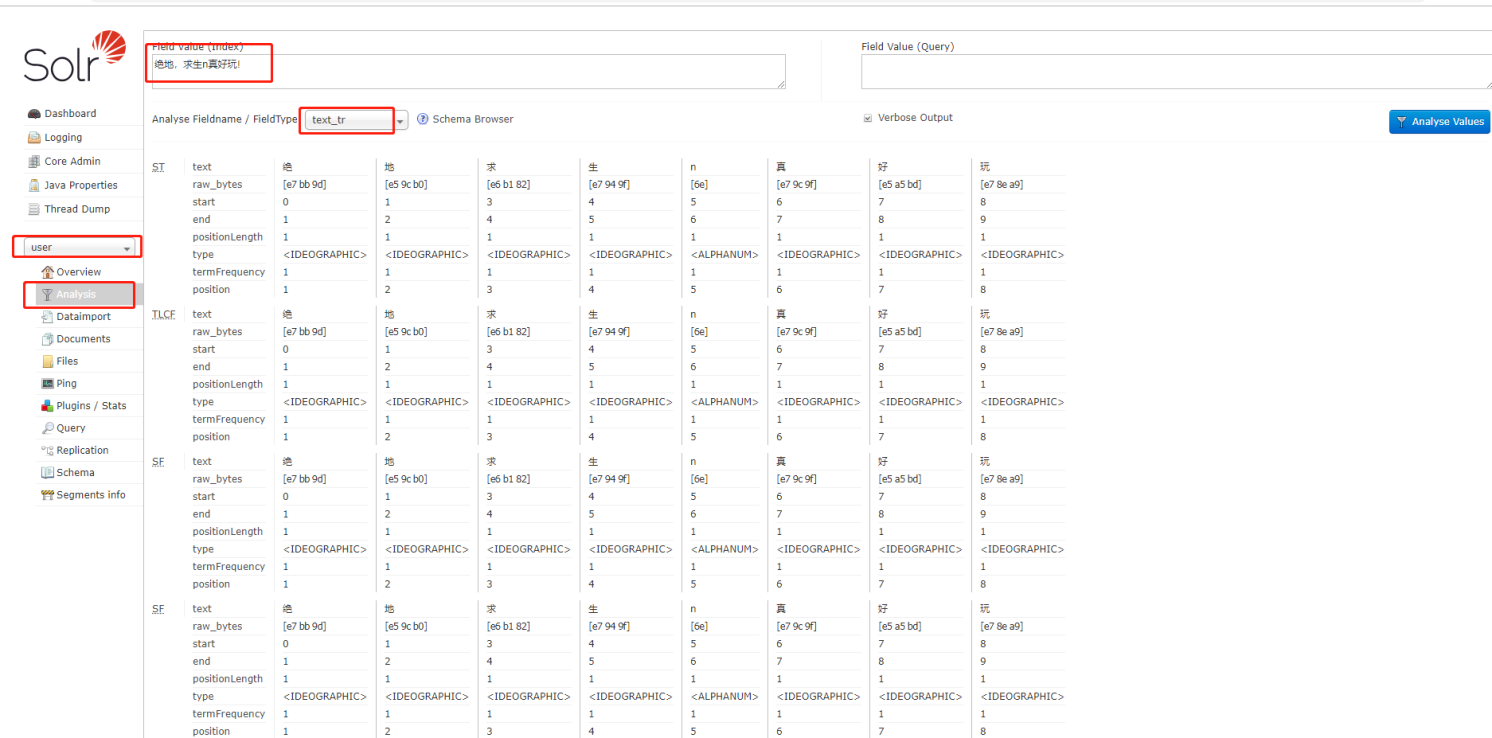
上传数据
Solr 可以接受来自许多不同来源的数据,包括 XML 文件、JSON文件、逗号分隔值(CSV)文件、从数据库表格中提取的数据以及常用文件格式(如 Microsoft Word 或 PDF)中的文件。
介绍3种方式,第一种方式用来上传数据库数据,后两种方式比较常见。
①Solr DataImportHandler
②HTTP 请求到 Solr 服务器来上传 XML 文件、json文件。XML格式的更新请求可以使用 Content-type: application/xml 或者 Content-type: text/xml 作为 XML 消息发送到更新处理程序;JSON 格式的更新请求可以使用 Content-Type: application/json 或 Content-Type: text/json 发送到 Solr 的 /update 处理程序。
③编写自定义 Java 应用程序以通过 SolrJ来获取数据(推荐)
前期准备: 添加field,与数据库表的字段对应起来
这是我们的数据源,将前5个作为字段传输。这里准备了435510 条数据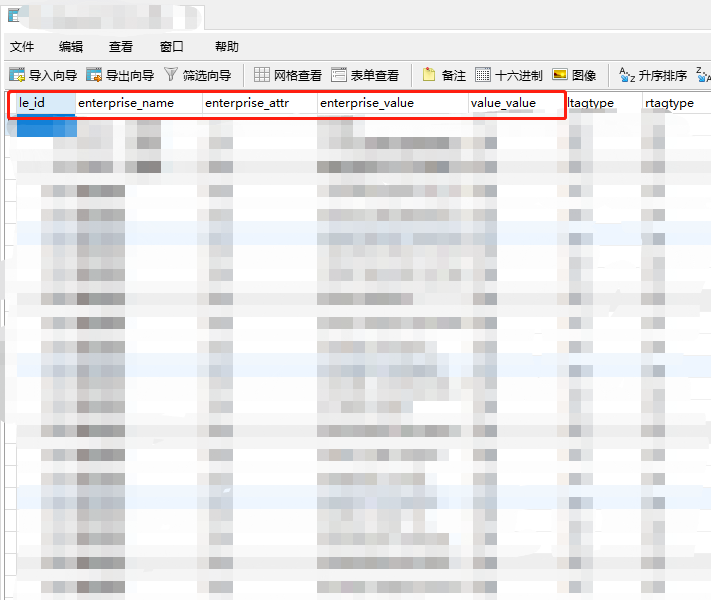
先确认。这5个字段,managed-schema没被定义过
使用Postman 批量添加field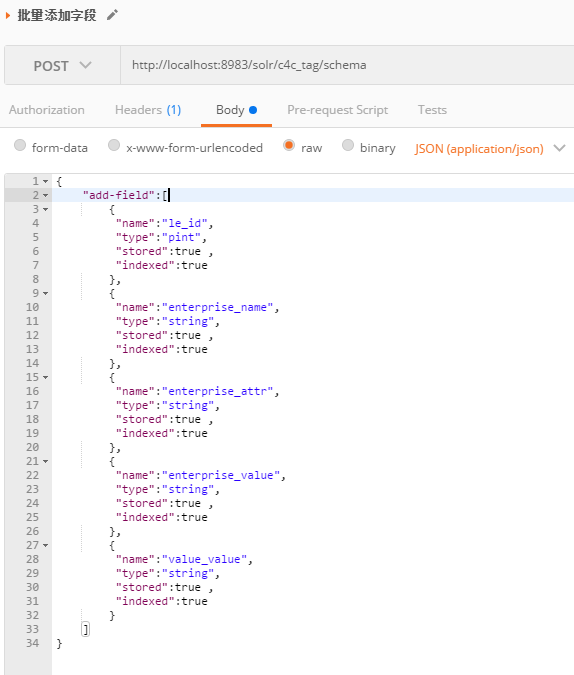
Solr DataImportHandler来上传数据库数据
DataImportHandler提供一种可配置的方式向Solr导入数据,可以全量导入,也可以增量导入,还可声明式提供可配置的任务调度,让数据定时从关系型数据库中更新数据到Solr服务器。详见
https://blog.csdn.net/qq_41674409/article/details/85143606
下载 mysql-connector-java-5.1.40.jar(版本不要太高,会不兼容) 添加到solr-8.4.1\server\solr-webapp\webapp\WEB-INF\lib 下。
将solr-dataimporthandler-8.4.1.jar 、solr-dataimporthandler-extras-8.4.1.jar 从 solr-8.4.1\dist 复制到solr-8.4.1\server\solr-webapp\webapp\WEB-INF\lib 下。
修改 solrconfig.xml 添加 dataImport 请求资源映射。添加在1
<config></config>

\solr-8.4.1\server\solr\user\conf目录下创建 data-config.xml,配置访问数据库的用户名、密码、查询语句,column对应数据库中字段、name对应solr的schema.xml中字段。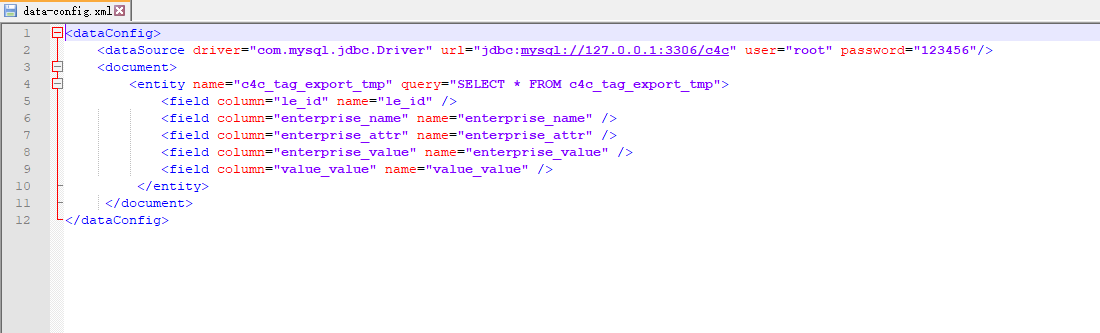
重启Solr: solr restart -p 8983
导入数据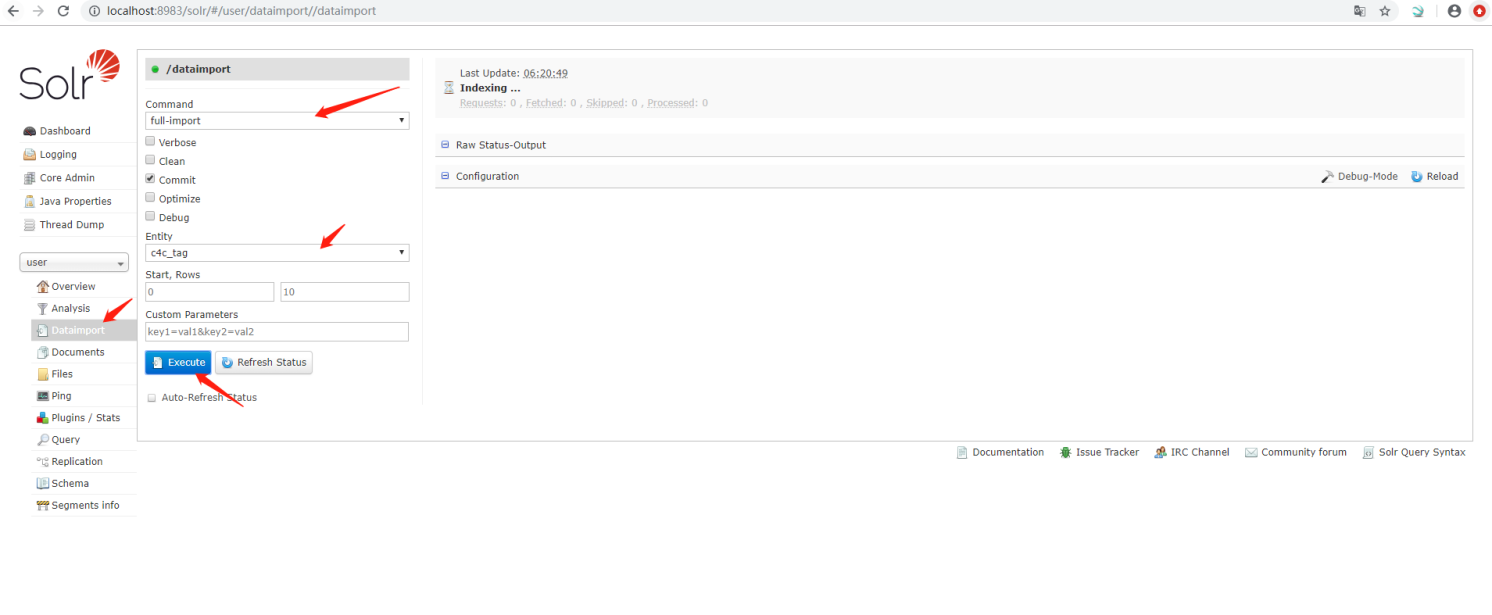
查看数据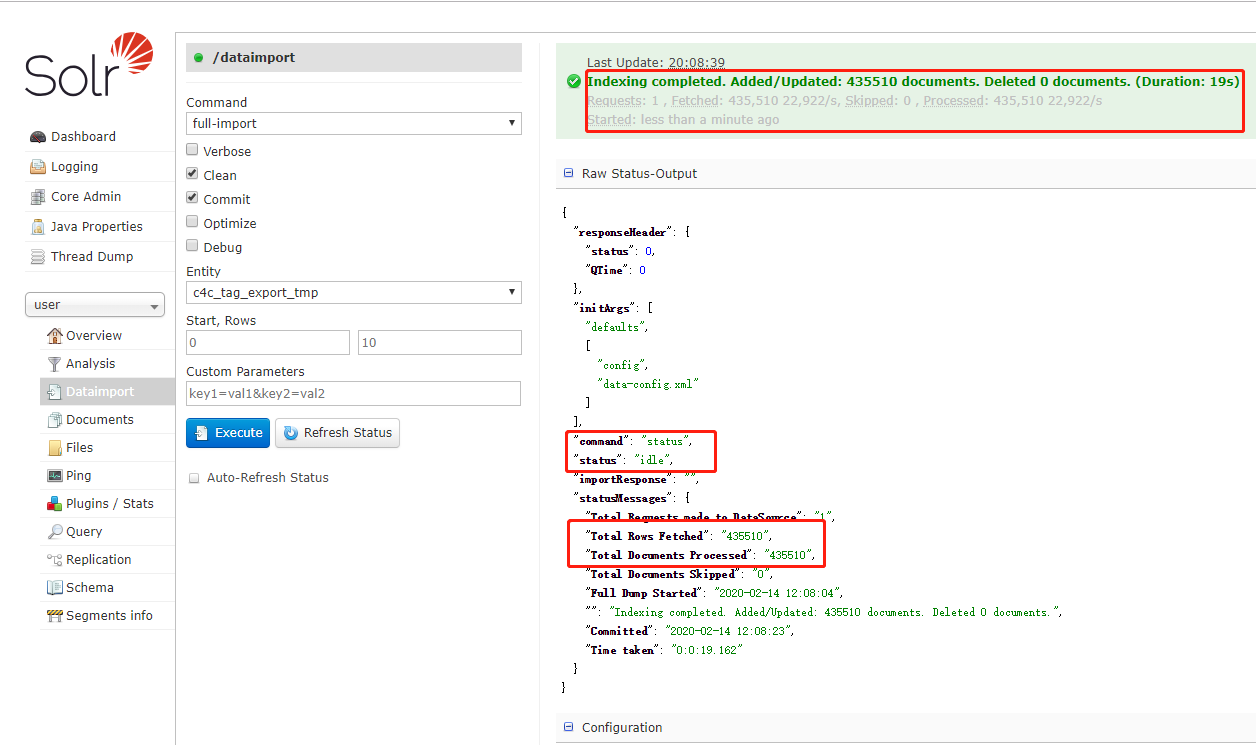
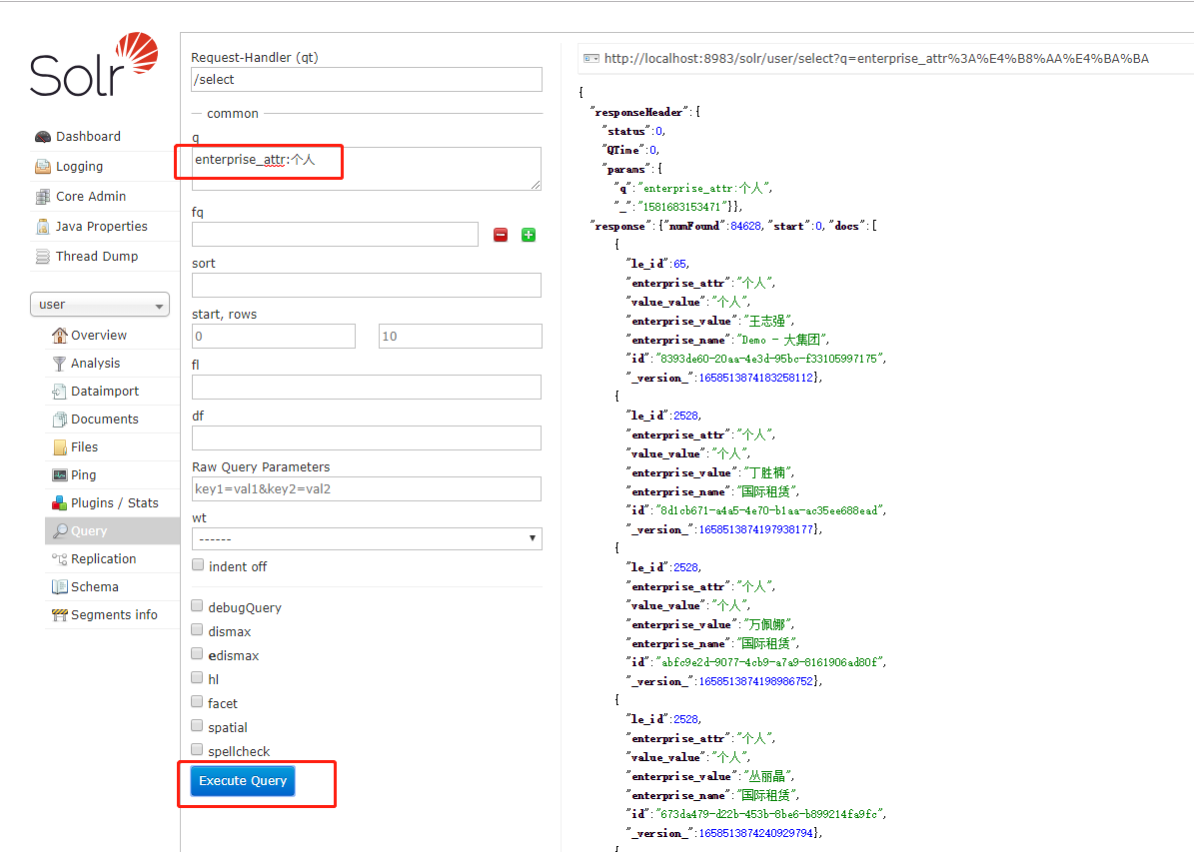
HTTP 请求到 Solr 服务器来上传 XML 文件
准备好满足条件的xml文件,格式为: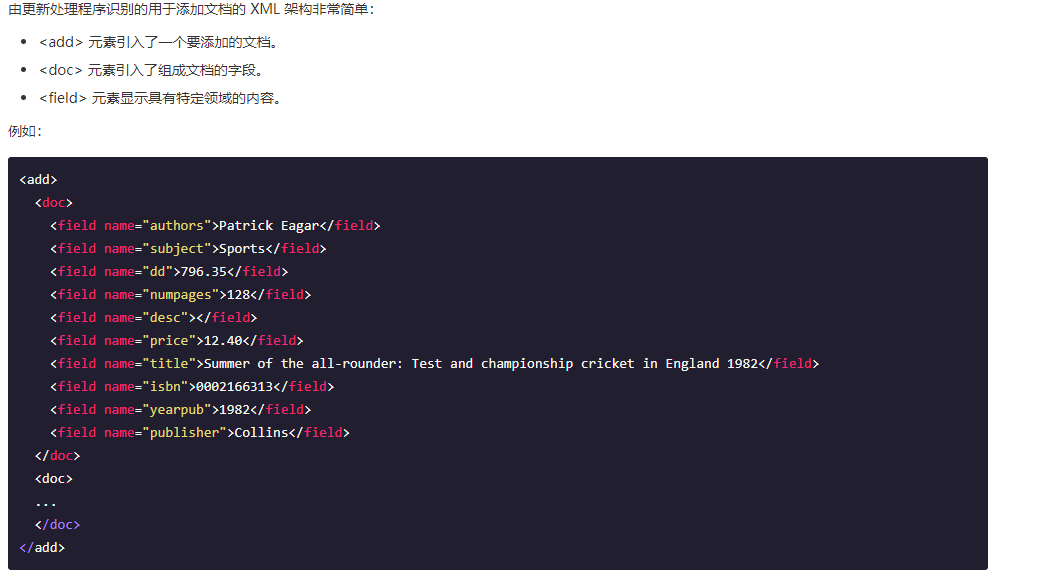
新开一个core,并配置field。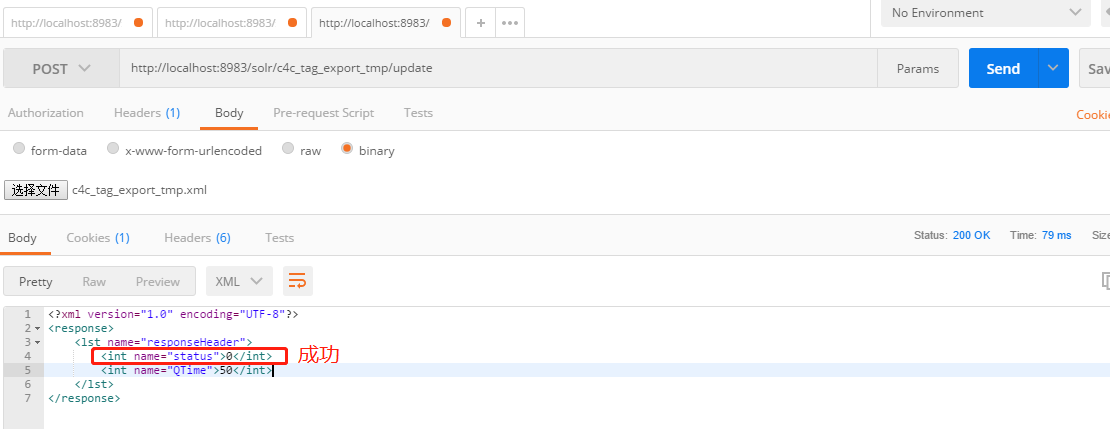
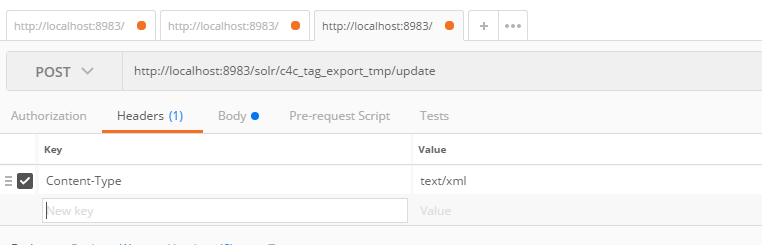
查看数据
编写自定义 Java 应用程序以通过 SolrJ来获取数据
SolrJ导入,放在下面SolrJ模块。
Solr搜索
Solr搜索的工作流程
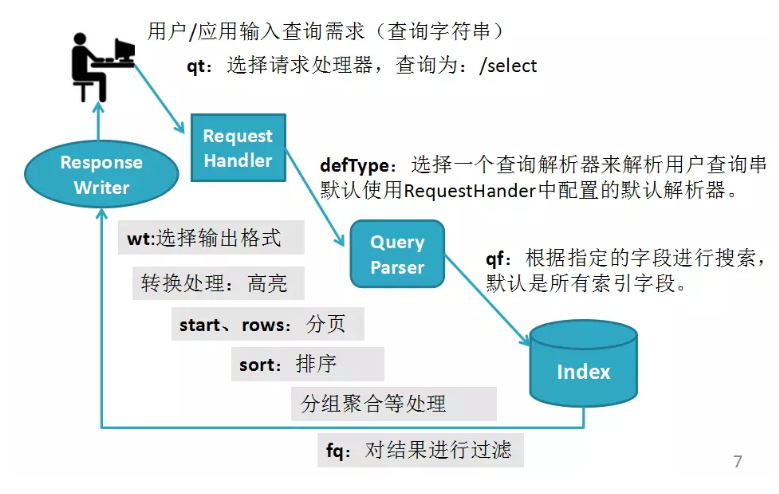
补充:下列这些情况,建议该字段配置docValues属性,提高性能。
需要聚合的字段,包括sort,agg,group,facet等 。
需要提供函数查询的字段。
需要高亮的字段。
通用查询参数
defType 参数
defType 参数指定 Solr 应该用来处理请求中的主查询参数(q)的查询解析器。1
defType=dismax
Solr中提供了三种解析器供选择:
lucene: solr的Standard Query Parser 标准查询解析器(默认)
dismax: DisMax Query Parser
edismax: Extended DisMax Query Parser (eDismax)sort 参数
sort 参数按升序 (asc) 或降序 (desc) 顺序排列搜索结果。1
sort=<field name><direction>,<field name><direction>],…
start 参数
分页查询的起始行号,默认为0;1
start=0
rows 参数
将查询的结果分页,返回最大文档数目。默认值是10。1
rows=20
fq(Filter Query)参数
fq 参数定义了一个查询,可以用来限制可以返回的文档的超集,而不影响 score。这对于加快复杂查询非常有用,因为指定的查询 fq 是独立于主查询而被缓存的。当以后的查询使用相同的过滤器时,会有一个缓存命中,过滤器结果从缓存中快速返回。
fq的传参说明:
在下面的例子中,只有流行度大于10并且段落为0的文档才会匹配。
可以一次传传多个fq:1
fq=popularity:[10 TO *]&fq=section:0
也可将多个过滤条件组合在一个fq:
1
fq=+popularity:[10 TO *] +section:0
每个过滤器查询的文档集都是独立缓存的,几个fq就缓存几个过滤结果集。
fl(Field List)参数
该 fl 参数将查询响应中包含的信息限制在指定的字段列表中。这些字段必须是 stored=”true” 或 docValues=”true”。
字段列表可以指定为空格分隔或逗号分隔的字段名称列表。
通配符 * 选择文档中的所有字段,它们是 stored=”true”、docValues=”true” 和 useDocValuesAsStored=”true”。
还可以添加伪字段(pseudo-fields)、函数和变换器。
示例:
函数与 fl:
可以为结果中的每个文档计算函数,并将其作为伪字段(pseudo-field)返回:1
fl=id,title,product(price,popularity)
文件变换器与 fl:
文档变换器可以用来修改查询结果中每个文档返回的信息:1
fl=id,title,[explain]
字段名称别名:
可以通过使用 “displayName” 前缀来更改对字段、函数或转换器的响应中使用的键。例如:1
l=id,sales_price:price,secret_sauce:prod(price,popularity),why_score:[explain style=nl]
debug 参数
用于指定在结果中返回调试信息。- timeAllowed 参数
限定查询在多少毫秒内返回,如果到时间了还未执行完成,则直接返回部分结果。 - wt 参数
指定响应的内容格式:json、xml、csv…… SearchHandler根据它选择ResponseWriter。默认JSON 将作为响应的格式返回。 - cache 参数
设置是否对查询结果、过滤查询的结果进行缓存。默认是都会被缓存的。如果不需要缓存明确设置 cache=false。
…
查询解析器
- 标准查询解析器
- DisMax 查询解析器
- 扩展的 DisMax 查询解析器
- 其他解析器
查询解析器插件是 QParserPlugin 的所有子类。可自定义扩展自己的查询分析器。
标准查询解析器
Solr 的标准查询解析器(Query Parser)也被称为 “lucene” 解析器。
标准查询解析器的关键优势在于它支持强大且相当直观的语法,允许您创建各种结构化查询。最大的缺点是它不容忍出现语法错误,与 DisMax 查询解析器相比, DisMax 查询解析器的设计目的是尽可能地减少抛出错误。
参数
q
使用标准查询语法定义查询。必须项。
……
响应
我们通过Solr Admin页面-Query来看看吧。内核user上,有我们之前存入的大量数据。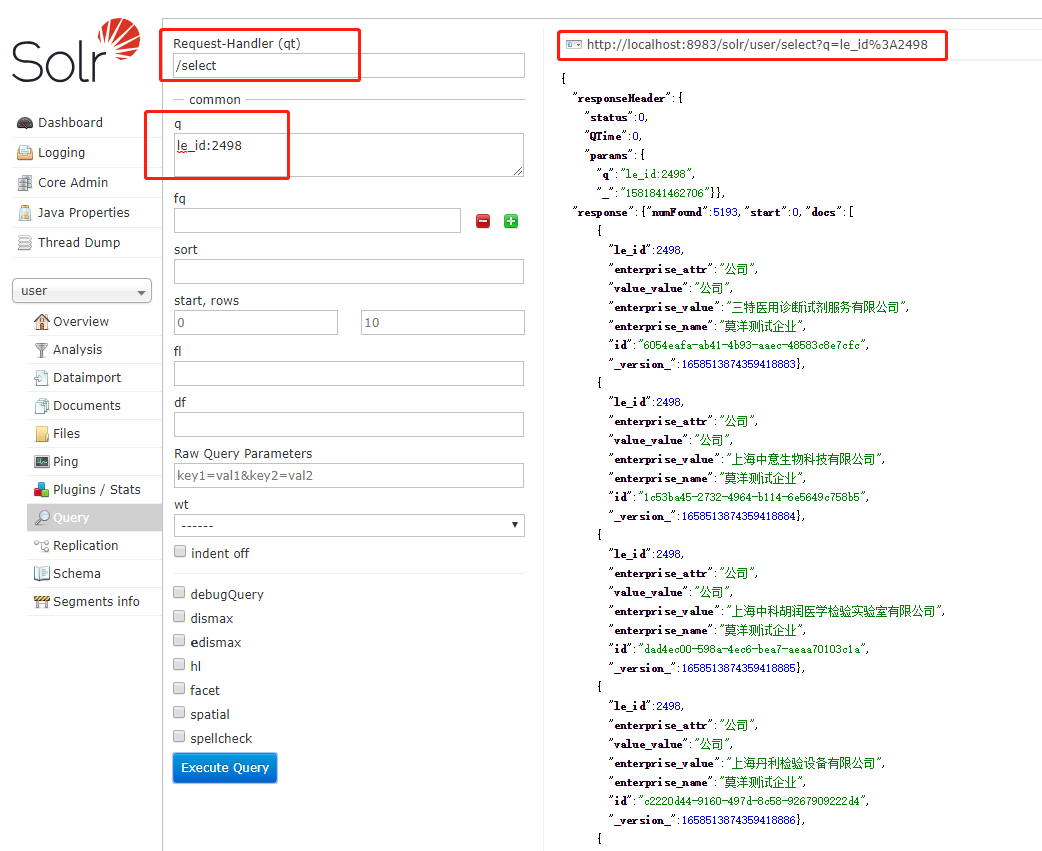
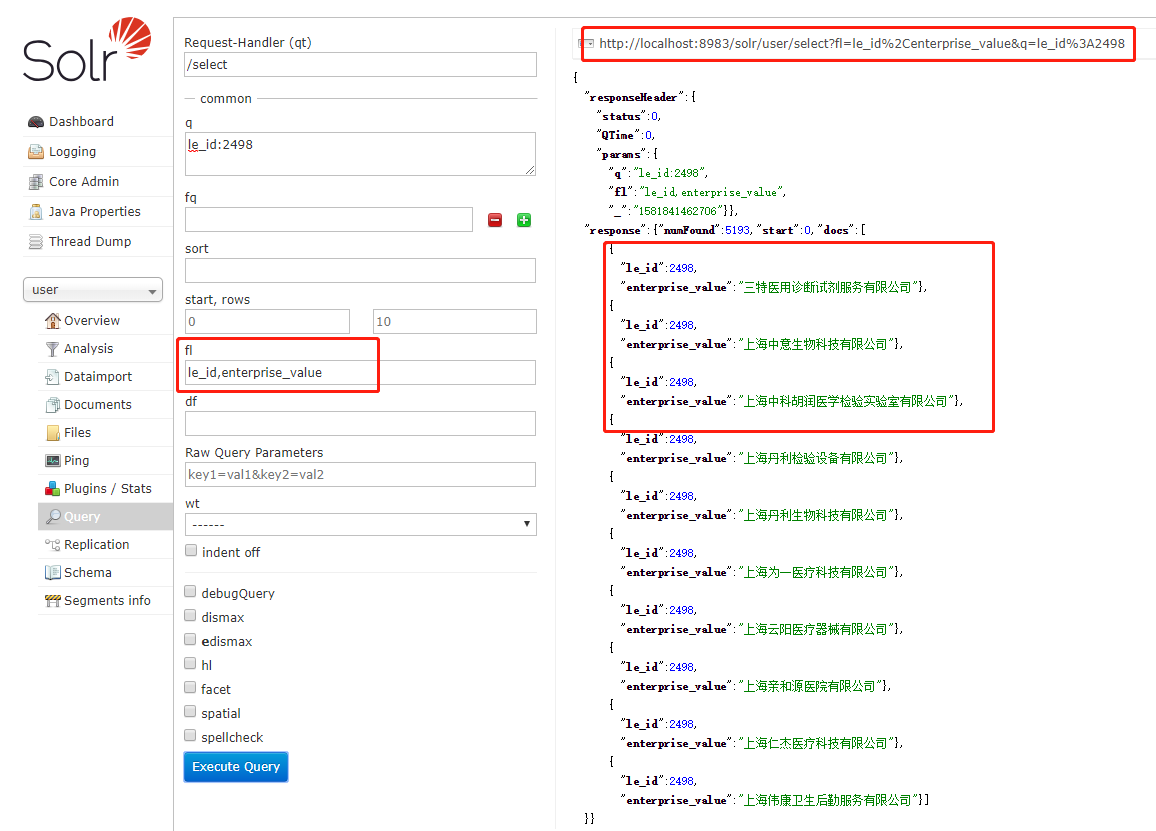
指定标准查询分析器的条件
检索词
有2种类型的检索词:单词和短语
- 单词是一个单独的词,例如 “test” 或 “hello”
- 短语是一组由双引号包围的词组,如 “hello dolly”
多个检索词可以与布尔运算符组合在一起,形成更复杂的查询(如下所述):
操作符
条件修饰
根据需要,Solr支持多样的能够增加灵活度或精度的检索词模糊匹配。这些模糊匹配包括可以进行模糊查询或一般查询的通配符。
- 通配符查询
solr标准查询支持在单词中使用一个或多个通配符。通配符可以应用于单词,但不能用于短语中。
通配符查询类型
字符
示例
单个字符(匹配单个字符)
?
搜索字符串te?t将匹配 test 和 text。
多个字符(匹配0个或多个字符)
*
tes* -> test, testing, 或 tester。
te*t -> test 或 text.
*est -> pest 或 test
模糊查询
在单词词尾添加波浪号 〜 符号1
roam~
这个搜索将匹配像 roams、foam、foams。它也将匹配“roam”这个词本身。
一个可选的距离参数指定的最大可编辑数介于0和2之间,默认为2。例如:1
roam~1
这将匹配 roams 和 foam 等术语,但不包括 foams,因为它的编辑距离为“2”。
邻近搜索
邻近查询将查询一个检索词与另一个检索词有指定距离的结果。
执行邻近查询,在查询检索词组最后添加~符号和一个数值。比如,要查询文档中的 “apache” 和 “jakarta” 之间有10个单词:1
"jakarta apache"~10
这里所说的距离,是匹配指定检索词所需移动单词的数量。在上面的例子中,“apache” 和 “jakarta” 之间有10个词的距离则匹配。如果 “apache” 在 “jakarta” 前面,则需要更大的数,使 “apache” 能够在 “jakarta” 后面。
范围搜索
范围搜索指定字段的值范围。如果是非数字字段,按照字典排序。
比如,下面的例子是匹配所有的mod_date检索字段在20020101和20030101之间的结果(包括20020101和20030101):1
mod_date:[20020101 TO 20030101]
范围查询不限于日期字段或数字格式,还可以查询非日期字段:
1
title:{Aida TO Carmen}
将会查询所有 title 在 Aida 与 Carmen之间的文档(不包括Aida 和 Carmen)。
通过括号决定是否包括上限和下限:
1.方括号[]表示包含上限和下限;
2.花括号{}表示不包含上限和下限;
3.也可以同时使用两种括号,表示一个包含,一个不包含,比如:count:{ 1 TO 10 ]。控制相关度查询
加权查询允许通过加权单词控制文档的相关度。比如,你查询 “jakarta apache” ,并且希望 “jakarta” 相关度更高,你可以使用 ^符号,比如:1
jakarta^4 apache
默认,加权因子是1。尽管加权因子必须是正数,但是可以小于1(比如,0.2)。
使用“^=”打分
常量打分查询使用 <query_clause>^=,对整个变量设置指定分值。当你只关心一个特定的匹配条件,不希望其他因素产生影响,比如检索词频率或逆文献频率。
例如:1
(description:blue OR color:blue)^=1.0 text:shoes
查询指定字段
在solr中对数据创建索引是以字段为基准的,这是在solr的managed-schema文件中定义的。
搜索可以利用字段增加查询精度。比如,你可以指定一个字段来搜索,比如一个title字段。
在managed-schema文件中定义一个字段作为默认字段。如果你在查询的时候没有指定字段,solr只搜索默认字段。另外,你可以在查询过程中指定一个字段或字段组合。
要指定一个字段,只需要在检索词前面加上字段和冒号(:),然后就能够使用这个字段进行查询了。
比如,假设一个索引包括两个字段,title和text,并且text是默认字段。如果你想查询查询名为The Right Way的文档和包含don’t go this way的文档,你可以使用下面的检索方法:1
2title:"The Right Way" AND text:"don't go this way"
title:"Do it right" AND "don't go this way"既然text是默认字段,可以不用明确指明;所以,上面第二种方式忽略它。
默认字段先于指定字段,所以查询title:Do it right将只在title字段查询Do,在默认字段上查询it和right。标准查询支持的布尔运算符
布尔运算符可以在查询时使用布尔逻辑,在匹配文档时查询存在或不存在指定检索词或条件。下面的表格总结了标准查询可以使用的布尔运算符。
布尔运算符
替代符号
描述
AND
&&
要求在布尔运算符两侧的任何一方都要匹配。
NOT
!
要求对应搜索词不存在。
OR
||
要求布尔运算符两侧一个或两个检索词都会出现。
+
要求符号”+”后的项必须在文档相应的域中存在
-
要求符号”-”后的项不存在。
布尔运算符允许使用逻辑运算符的组合检索词。Lucene支持AND、+、OR、NOT和-作为逻辑运算符。
注:
当使用关键词(如AND、NOT)指定布尔表达式时,必须使用大写字母。布尔运算符OR (||)
OR运算符是默认运算符。这就意味着,如果两个检索词之间没有布尔表达式,默认使用OR运算符。OR运算符链接的两个检索词,如果任何一个检索词存在文档中,这个文档将成为匹配文档。这就相当于并集。可以使用||代替OR。查询包含 “jakarta apache” 或 “jakarta,”,可以使用1
2"jakarta apache" jakarta
"jakarta apache" OR jakarta布尔运算符AND (&&)
AND操作要求在一个文档中包含两个检索词,这相当于交集。可以使用&&代替AND。
要查询包含 “jakarta apache” 和 “Apache Lucene”的文档,可以使用1
2"jakarta apache" AND "Apache Lucene"
"jakarta apache" && "Apache Lucene"布尔运算符NOT (!)
NOT运算符不包括那些包含NOT之后的检索词的文档。这相当于差集。可以使用!代替NOT。
要查询包含 “jakarta apache” 但不包括 “Apache Lucene”的文档,可以使用1
2"jakarta apache" NOT "Apache Lucene"
"jakarta apache" ! "Apache Lucene"布尔运算符+
+要求+之后检索词存在于至少一个文档的某个字段中,以便查询返回。
比如,要查询文件,必须包含”jakarta”,可能或可能不包含”lucene”,可以使用查询1
+jakarta lucene
布尔运算符-
-或“禁止”运算符不包括符号后包含检索词的文件。
比如,要查询文件,必须包含”jakarta apache”,不包含”Apache Lucene”,可以使用查询1
"jakarta apache" -"Apache Lucene"
转义特殊字符
在solr的一次查询中,下列字符存在特殊含义:+ - && || ! ( ) { } [ ] ^ “ ~ * ? : /。
为了让solr解读这些字符时使用字面量,而不是特殊字符,可以在字符前加一个反斜杠\字符。例如,查询(1+1):2,为了不让solr把+、括号()对两个检索词进行子查询,需要在特殊字符前加上反斜杠转义字符:\(1\+1\)\:2。分组子查询
支持使用括号来组合子句形式的子查询。如果你想控制一个查询的布尔逻辑,这是非常有用的。
The query below searches for either “jakarta” or “apache” and “website”:
下面的查询搜索 “jakarta” 或 “apache” 和 “website”:(jakarta OR apache) AND website。
这样增加了查询的准确性,“website”必须存在,需要”jakarta” 或 “apache” 存在。group从句作为字段
在查询过程中多一个字段使用两个或多个布尔运算符,需要使用括号组织布尔从句。比如,下面查询title字段必须包含”return”单词和”pink panther”短语:title:(+return +”pink panther”)。注释
在查询串中支持C语言风格的注释。比如:”jakarta apache” /* 这是在一个普通查询串中间的注释 */ OR jakarta。注释可以被嵌套。
DisMax 查询解析器
DisMax查询解析器设计用于处理用户输入的简单短语(无复杂语法),并根据每个字段的重要性使用不同的权重(升序)在多个字段中搜索单个术语。其他选项允许用户根据特定于每个用例的规则(独立于用户输入)影响分数。
一般来说,与“Lucene”Solr查询解析器的接口相比,DisMax查询解析器的接口更像Google的接口。这种相似性使DisMax成为许多用户应用程序的适当查询解析器。它接受一个简单的语法,很少产生错误消息。
DisMax查询解析器主要设计为易于使用,并且几乎可以接受任何输入而不返回错误。
语法:略
扩展的 DisMax 查询解析器:eDismax
除了支持所有的 DisMax 查询解析器参数外,同时支持完整的 Lucene 查询分析器语法,它与 Solr 的标准查询解析器具有相同的增强功能。
Solr的函数查询
函数查询允许你使用一个或多个数字字段的真实值生成一个相关性分数,函数查询在standard,DisMax,eDisMax下都能使用。
查询函数可以是常量,字段或者其他函数的组合。使用函数可以影响结果的排序。
使用Function Query
直接向QParser指定函数参数,如func或frange:
1
q={!func}div(popularity,price)&fq={!frange l=1000}customer_ratings
在排序时使用
1
sort=div(popularity,price) desc, score desc
将函数的结果作为伪字段(pseudo-fields)添加到查询结果中的文档
1
&fl=sum(x, y),id,a,b,c,score
指定函数的一个参数:在dDisMax中指定boost参数,在DisMax中指定bf参数
1
q=dismax&bf="ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3"
在Lucene的QParser中使用val关键字指定函数
1
q=_val_:mynumericfield _val_:"recip(rord(myfield),1,2,3)"
使用Function Query
Solr中的可用函数
todo
响应编写器
Solr 支持各种响应编写器,以确保查询响应可以被适当的语言或应用程序解析。
该 wt 参数选择要使用的响应编写器。
- JSON
- XML
- CSV
- GeoJSON
- javabin
- PHP
- PHPS
- python
- ruby
- smile
- velocity
- XLSX
- XSLT
JSON响应编写器
默认的 Solr 响应编写器是 JsonResponseWriter。在请求中没有设置 wt 参数,则默认情况下将获得 JSON。
参数介绍:略
标准的XML响应编写器
XML 响应编写器是 Solr 当前包含的最通用和可重用的响应编写器。这是大多数关于 Solr 查询响应的讨论和文档中使用的格式。
参数介绍:略
Solr的提交方式
Solr的提交方式有两种,标准提交(硬提交,hard commit)和软提交(soft commit)。
Hard commit
- 默认的提交即硬提交,commit之后会立刻将文档同步到硬盘,在开启新搜索器之前会阻塞,直到同步完成。
- 默认情况下commit后会开启一个新搜索器(newSearcher),然后进行预热,预热完成后顶替旧搜索器,使旧缓存失效,但是开启新searcher及预热的过程(IO消耗)耗费资源过大,且可能被阻塞,所以应尽量避免在高峰期开启newsearcher,搜索器同一时间只能有一个处于active状态。
- 为了避免频繁commit,solr提供了autocommit功能,可以设置每隔多久提交一次,或者待提交文档量达到阀值提交一次,并且可定义是否在提交后开启新的搜索器,若不开启,则缓存不能够被刷新,新更新文档不能够被实时读取到。
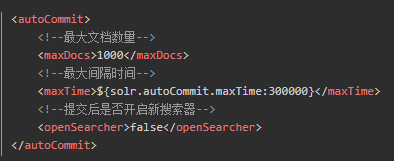
Soft commit
- 软提交是将文档提交到内存,并不实时写入硬盘,减少了耗时的I/O操作。
- 为了保证实时搜索,solr在软提交基础上引入了近实时搜索(NRT),NRT并不会被文档更新所阻塞,也不会等待文档合并完成再打开一个搜索器。
- 在lucene4.x 之前,solr采用NRTManager实现NRT,之后使用ControlledRealTimeReopenThread实现,它通过IndexWriter对象来监控内存中的文档变化,从而得到最新的文档信息,该过程既不需要高耗时的I/O操作,也不需要刷新搜索器,所以非常之快,耗费资源很少。
- 所以近实时搜索(NRT)是软提交的一个特性。
- 同样的软提交也支持自动提交的方式,配置如下:
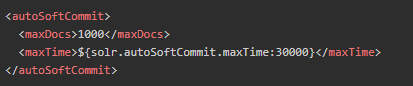
结合优化
上述两种提交方式并不冲突,试想我们程序使用了软提交,但何时可以把数据真正同步到磁盘呢?这时候就可以两者结合达到目的。我们设置每隔5000ms进行一次软提交,文档存入了内存,也可以实时搜索,然后每隔300000ms又会进行进行一次硬提交,同步到磁盘,无需刷新Searcher,如此两者兼顾。在配置文件中配置后,在客户端就不需要维护提交方式和提交时间了。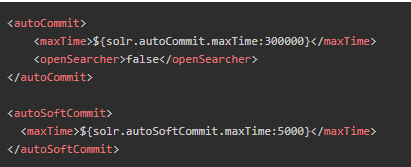
导出Solr结果集
介绍
- 可以使用特殊的秩查询解析器和响应编写器来导出完全排序的结果集,这种解析器和响应编写器专门设计用于处理涉及排序和导出数百万条记录的场景。
- 此功能使用 stream 排序技术,在毫秒内开始发送记录,并继续对结果进行 stream 处理,直到整个结果集被排序并且导出为止。
- 此功能可能有用的情况包括:会话分析、分布式合并联接、时间序列汇总、高基数字段上的聚合、完全分布式字段合并和基于排序的统计信息。
请求结果导出
- 可以使用 /export 来请求导出查询的结果集。
- 所有查询都必须包括 sort 和 fl 参数,否则查询将返回一个错误。过滤器查询也被支持。
- 受支持的响应编写器是 json 和 javabin。由于向后兼容性的原因,wt=xsort也被支持作为输入,但是 wt=xsort 与 wt=json 的行为相同。默认的输出格式是 json。
示例:1
http://localhost:8983/solr/core_name/export?q=my-query&sort=severity+desc,timestamp+desc&fl=severity,timestamp,msg
SolrJ
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图: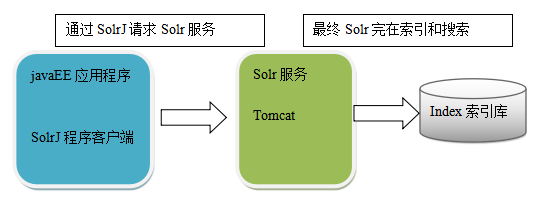
demo代码:详见cfa-tagging项目的SolrJTest.java。
SolrTag类定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51//忽略未匹配到的字段
(ignoreUnknown = true)
public class SolrTag {
// solr查询若直接将数据转为对象,需要指定Field,该值需要和managed-schema配置Field的name一致
("leId")
private Integer leId;
("enterpriseName")
private String enterpriseName;
("enterpriseAttr")
private String enterpriseAttr;
("enterpriseValue")
private String enterpriseValue;
("valueValue")
private String valueValue;
public Integer getLeId() {
return leId;
}
public void setLeId(Integer leId) {
this.leId = leId;
}
public String getEnterpriseName() {
return enterpriseName;
}
public void setEnterpriseName(String enterpriseName) {
this.enterpriseName = enterpriseName;
}
public String getEnterpriseAttr() {
return enterpriseAttr;
}
public void setEnterpriseAttr(String enterpriseAttr) {
this.enterpriseAttr = enterpriseAttr;
}
public String getEnterpriseValue() {
return enterpriseValue;
}
public void setEnterpriseValue(String enterpriseValue) {
this.enterpriseValue = enterpriseValue;
}
public String getValueValue() {
return valueValue;
}
public void setValueValue(String valueValue) {
this.valueValue = valueValue;
}
public String toString() {
return "SolrTag [leId=" + leId + ", enterpriseName=" + enterpriseName + ", enterpriseAttr=" + enterpriseAttr
+ ", enterpriseValue=" + enterpriseValue + ", valueValue=" + valueValue + "]";
}SolrJTest单元测试类定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326/**
* Description : SolrJ CRUD操作的单元测试类
*/
(SpringRunner.class)
@SpringBootTest
@WebAppConfiguration
public class SolrJTest {
SolrTagMapper solrTagMapper;
private SolrClient solrClient;
/**
* 初始化SolrClient
*/
public void setUp() throws Exception {
String solrUrl = "http://localhost:8983/solr/c4c_tag";
solrClient = new HttpSolrClient.Builder(solrUrl).build();
}
/**
* 查询所有字段
*/
public void queryFields() throws Exception {
SchemaRequest.Fields queryFields = new SchemaRequest.Fields();
NamedList<Object> existFields = solrClient.request(queryFields);
Iterator<Entry<String, Object>> iter = existFields.iterator();
while (iter.hasNext()) {
Entry<String, Object> next = iter.next();
System.out.println(next.getKey() + ":" + next.getValue());
}
}
/**
* 添加字段,包括字段的名称、类型、是否存储,是否索引等
*/
public void addFields() throws Exception {
List<Map<String, Object>> fieldAttributesList = new ArrayList<>();
Map<String, Object> fieldAttributes = new HashMap<>();
// 域名
fieldAttributes.put("name", "leId");
// 域的类型,可以是string,pint,如果需要分词设为text_ik
fieldAttributes.put("type", "pint");
// 是否索引,默认为true
fieldAttributes.put("indexed", true);
// 是否存储,默认为true
fieldAttributes.put("stored", true);
// 是否多值,默认为false
fieldAttributes.put("multiValued", false);
// 是否必须,默认false,schema文件中有一个id已默认必须
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "enterpriseName");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "enterpriseAttr");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "enterpriseValue");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
fieldAttributes = new HashMap<>();
fieldAttributes.put("name", "valueValue");
fieldAttributes.put("type", "string");
fieldAttributes.put("indexed", true);
fieldAttributes.put("stored", true);
fieldAttributes.put("multiValued", false);
fieldAttributes.put("required", false);
fieldAttributesList.add(fieldAttributes);
SchemaRequest.AddField addField = null;
for (Map<String, Object> map : fieldAttributesList) {
addField = new SchemaRequest.AddField(map);
solrClient.request(addField);
}
}
/**
* 添加字段,包括字段的名称、类型、是否存储,是否索引等
*/
public void deleteField() throws Exception {
SchemaRequest.DeleteField delField = new SchemaRequest.DeleteField("delField");
solrClient.request(delField);
}
/**
* 通过对象添加单条数据,若添加时id已存在,那么solr会执行修改操作
*/
public void addBean() throws Exception {
SolrTag tag = new SolrTag();
tag.setLeId(1);
tag.setEnterpriseName("国企");
tag.setEnterpriseAttr("2-5 年");
tag.setEnterpriseValue("AA有限公司");
tag.setValueValue("IT行业");
solrClient.addBean(tag);
solrClient.commit();
}
/**
* 批量添加
*/
public void addBeans() throws Exception {
// 从数据库查出所有的记录
List<SolrTag> solrTags = solrTagMapper.listAll();
// 添加
solrClient.addBeans(solrTags);
solrClient.commit();
}
/**
* 通过document添加单条数据
*/
public void addDocument() throws Exception {
SolrInputDocument document = new SolrInputDocument();
document.addField("leId", 2);
document.addField("enterpriseName", "国企");
document.addField("enterpriseAttr", "3年以上");
document.addField("enterpriseValue", "BB有限公司");
document.addField("valueValue", "IT行业");
solrClient.add(document);
solrClient.commit();
}
/**
* 两种删除方式
*/
public void deleteById() throws Exception {
// 方式一:根据id删除
// solrClient.deleteById(id);
// 方式二:根据查询结构删除
solrClient.deleteByQuery("enterpriseName:国企");
solrClient.commit();
}
/**
* 查询所有/select?q=*:*
*/
public void queryAll() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 限定返回字段/select?q=*:*&fl=param1,param2
*/
public void queryFl() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 设置限定返回字段
solrQuery.setFields("leId", "enterpriseName", "enterpriseAttr");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 分页/select?q=*:*&rows=5&start=0
*/
public void queryPage() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 设置分页信息
solrQuery.setStart(0);
solrQuery.setRows(20);
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 增加限定条件/select?q=*:*&fq=leId:{70 TO *]&fq=valueValue:公司
*/
public void queryFq() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 设置限定条件
solrQuery.setFilterQueries("leId:{70 TO *]", "valueValue:公司");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 使用函数,并设置别名/select?q=*:*&fl:"leId", "alias:sum(leId,0.1)", "valueValue"
*/
public void queryFunction() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 将函数的结果作为伪字段,添加到查询结果中的文档
solrQuery.setFields("leId", "alias:sum(leId,0.1)", "valueValue");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 添加排序/select?q=*:*&sort:leId desc
*/
public void querySort() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 添加排序
solrQuery.setSort("leId", SolrQuery.ORDER.desc);
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果
List<SolrTag> solrTags = response.getBeans(SolrTag.class);
// 打印匹配总数
System.out.println("匹配总数为:" + response.getResults().getNumFound());
// 打印搜索结果
for (SolrTag solrTag : solrTags) {
System.out.println(solrTag);
}
}
/**
* 分组/select?q=*:*&group.limit=20&group.offset=0&group.ngroups=true&wt=javabin&version=2&group.field=enterpriseName&group=true
* group=true:设置开启分组查询 group.field=xx:设置分组字段 group.limit=20:设置分组后展示分组下数据量
* group.ngroups=true:设置为true表示会返回分组的分组
*/
public void queryGroup() throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery("*:*");
// 开启分组功能
solrQuery.set(GroupParams.GROUP, true);
// 按照enterpriseName分组
solrQuery.set(GroupParams.GROUP_FIELD, "enterpriseName");
// 设置每个分组里从第几条数据开始返回,用于组内分页,这里不进行分页
solrQuery.set(GroupParams.GROUP_OFFSET, 0);
// 设置每个分组最多返回几条数据
solrQuery.set(GroupParams.GROUP_LIMIT, 20);
// 是否返回总的组数
solrQuery.set(GroupParams.GROUP_TOTAL_COUNT, true);
// //组内排序
// solrQuery.set(GroupParams.GROUP_SORT,"filed asc");
// //组间排序
// solrQuery.set(CommonParams.SORT,"filed desc");
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// 获取查询结果列表
GroupResponse groupResponse = response.getGroupResponse();
// 获取根据不同分组方式查询到的结果
List<GroupCommand> groupCommandList = groupResponse.getValues();
// 由于这里只有一种分组策略,所以直接取第一个对象
GroupCommand groupCommand = groupCommandList.get(0);
List<Group> groups = groupCommand.getValues();
// 打印每个分组信息
SolrDocumentList list = null;
for (Group group : groups) {
// 获取每个分组内的数据
list = group.getResult();
System.out.println("------------");
for (SolrDocument solrDocument : list) {
// 方便演示,直接转换成json打印
String record = JSON.toJSONString(solrDocument);
System.out.println(record);
}
}
}
}
其它
以下内容属于Solr可选扩展功能:
- 身份验证插件
- hadoop
- 授权插件
- 签名证书SSL
- HDFS存储
- 备份与还原
- ……
以下内容属于集群SolrCloud的功能:
- SolrCloud介绍
- SolrCloud集群部署
- SolrCloud工作原理
- 碎片、副本、索引数据
- 分布式请求
- 扩展与容错
- ZooKeeper搭建
- ZooKeeper控制访问
- ZooKeeper管理配置文件
- SolrCloud的Collections API
- 流表达式
- 并行SQL接口
- 并行SQL体系结构的三个逻辑层组成。
- ……


